Note
Go to the end to download the full example code.
Example 02: Walk-Forward Cross-Validation with Gap Enforcement¶
This example demonstrates temporalcv’s walk-forward CV implementation, which prevents the #1 source of data leakage in time-series ML: using future information during training.
Real-World Case Study: M3 Competition Monthly Series¶
The M3 Competition (Makridakis et al., 2000) is a foundational benchmark for forecasting methods. We use it to demonstrate:
Gap enforcement: For h-step forecasting, the gap between train and test must be >= h to prevent target leakage.
Window strategies: Expanding vs sliding windows have different tradeoffs — sliding forgets old data but adapts to regime changes.
sklearn integration: WalkForwardCV is a drop-in replacement for TimeSeriesSplit with better gap handling.
Key Insight¶
Standard sklearn TimeSeriesSplit has a gap parameter, but doesn’t enforce that gap >= horizon. temporalcv.WalkForwardCV makes this explicit and provides detailed split metadata for debugging.
Usage¶
# Requires M3 data (auto-downloaded): pip install temporalcv[monash] python 02_walk_forward_cv.py
# Without M3 data (uses synthetic): python 02_walk_forward_cv.py
Requirements¶
pip install temporalcv[monash] # For M3 data # or pip install temporalcv scikit-learn # Minimum requirements
======================================================================
TEMPORALCV: Walk-Forward Cross-Validation
======================================================================
Note: Using synthetic data (pip install temporalcv[monash] for M3)
Data source: Synthetic (monthly-like)
Series length: 150
Forecast horizon: 12 steps
Feature matrix: (138, 12)
======================================================================
PART 1: Basic Walk-Forward CV (Expanding Window)
======================================================================
CV Configuration: WalkForwardCV(n_splits=5, window_type='expanding', window_size=None, extra_gap=0, test_size=12)
Split Structure:
------------------------------------------------------------
Split 0: Train [ 0- 77] ( 78 samples) | Gap: 0 | Test [ 78- 89] (12 samples)
Split 1: Train [ 0- 89] ( 90 samples) | Gap: 0 | Test [ 90-101] (12 samples)
Split 2: Train [ 0-101] (102 samples) | Gap: 0 | Test [102-113] (12 samples)
Split 3: Train [ 0-113] (114 samples) | Gap: 0 | Test [114-125] (12 samples)
Split 4: Train [ 0-125] (126 samples) | Gap: 0 | Test [126-137] (12 samples)
CV Scores (MAE): ['2.53', '5.17', '4.94', '4.99', '5.37']
Mean MAE: 4.60 (+/- 1.05)
======================================================================
PART 2: Gap Enforcement for Multi-Step Forecasting
======================================================================
Problem: Forecasting 12 steps ahead (h=12)
Without gap enforcement, training targets leak test information!
--- WITHOUT Gap (WRONG for h-step) ---
Split 0: Train ends at 101, Test starts at 102, Gap=0 → LEAKAGE!
Split 1: Train ends at 113, Test starts at 114, Gap=0 → LEAKAGE!
Split 2: Train ends at 125, Test starts at 126, Gap=0 → LEAKAGE!
--- WITH Gap >= Horizon (CORRECT) ---
Split 0: Train ends at 89, Test starts at 102, Gap=12 → OK
Split 1: Train ends at 101, Test starts at 114, Gap=12 → OK
Split 2: Train ends at 113, Test starts at 126, Gap=12 → OK
======================================================================
PART 3: Expanding vs Sliding Window Comparison
======================================================================
Window size: 60 observations
--- Expanding Window ---
Training set grows over time (uses all historical data)
Split 0: Train size = 78
Split 1: Train size = 90
Split 2: Train size = 102
Split 3: Train size = 114
Split 4: Train size = 126
Mean MAE: 4.60
--- Sliding Window ---
Training set is fixed size (adapts to regime changes)
Split 0: Train size = 60
Split 1: Train size = 60
Split 2: Train size = 60
Split 3: Train size = 60
Split 4: Train size = 60
Mean MAE: 4.79
--- Comparison ---
Expanding window MAE: 4.60
Sliding window MAE: 4.79
→ Expanding window performs better (more data helps)
======================================================================
PART 4: sklearn Integration
======================================================================
WalkForwardCV is sklearn-compatible:
✓ BaseCrossValidator subclass
✓ Works with cross_val_score, GridSearchCV, etc.
✓ Provides get_n_splits(), split(), __repr__
Example with cross_val_score:
from sklearn.model_selection import cross_val_score
from temporalcv import WalkForwardCV
cv = WalkForwardCV(n_splits=5, horizon=12, extra_gap=0)
scores = cross_val_score(model, X, y, cv=cv, scoring='neg_mean_absolute_error')
======================================================================
KEY TAKEAWAYS
======================================================================
1. ALWAYS use walk-forward CV for time-series (not random splits!)
- Temporal ordering must be preserved
- Training set must come before test set chronologically
2. SET horizon=h for h-step forecasting (extra_gap optional for safety margin)
- For 12-month ahead forecasts, use horizon=12, extra_gap=0 (minimum safe)
- Add extra_gap > 0 for additional temporal separation if desired
3. CHOOSE window type based on your data:
- Expanding: Use all history (good for stable processes)
- Sliding: Fixed window (good for regime changes, concept drift)
4. USE get_split_info() to debug and visualize splits
- See exactly what data is in train vs test
- Verify gaps are correct before training
5. INTEGRATE with sklearn ecosystem
- cross_val_score, GridSearchCV, RandomizedSearchCV all work
- Drop-in replacement for TimeSeriesSplit with better gap handling
Note: Using synthetic data (pip install temporalcv[monash] for M3)
from __future__ import annotations
import warnings
import numpy as np
from sklearn.linear_model import Ridge
from sklearn.metrics import mean_absolute_error
from temporalcv.cv import WalkForwardCV
from temporalcv.gates import gate_temporal_boundary
from temporalcv.viz import CVFoldsDisplay
warnings.filterwarnings("ignore")
# =============================================================================
# Data Loading
# =============================================================================
def load_forecasting_data() -> tuple[np.ndarray, int, str]:
"""
Load M3 monthly data or generate realistic synthetic series.
Returns
-------
series : np.ndarray
Single time series (1D array)
horizon : int
Standard forecast horizon for this frequency
source : str
Data source description
"""
try:
from temporalcv.benchmarks import load_m3
dataset = load_m3(subset="monthly", sample_size=1)
# M3 returns multi-series; take first one
series = dataset.values[0]
horizon = dataset.metadata.horizon # 18 for monthly
return series, horizon, "M3 Competition (monthly)"
except Exception:
print("Note: Using synthetic data (pip install temporalcv[monash] for M3)")
return _generate_synthetic_series(), 12, "Synthetic (monthly-like)"
def _generate_synthetic_series(
n_samples: int = 150,
seed: int = 42,
) -> np.ndarray:
"""
Generate synthetic monthly-like series with trend and seasonality.
"""
rng = np.random.default_rng(seed)
t = np.arange(n_samples)
# Components
trend = 100 + 0.5 * t # Upward trend
seasonality = 15 * np.sin(2 * np.pi * t / 12) # Annual cycle
noise = rng.normal(0, 5, n_samples)
return trend + seasonality + noise
# =============================================================================
# Feature Engineering (Proper Temporal Alignment)
# =============================================================================
def create_lagged_features(
series: np.ndarray,
n_lags: int = 12,
) -> tuple[np.ndarray, np.ndarray]:
"""
Create lagged features for forecasting.
For h-step forecasting, we predict y[t+h] using features from y[t], y[t-1], ...
This function creates features aligned for 1-step ahead prediction.
"""
n = len(series)
features = []
for lag in range(1, n_lags + 1):
lagged = np.full(n, np.nan)
lagged[lag:] = series[:-lag]
features.append(lagged)
X = np.column_stack(features)
y = series.copy()
# Remove rows with NaN
valid_mask = ~np.isnan(X).any(axis=1)
return X[valid_mask], y[valid_mask]
# =============================================================================
# Demonstration: Walk-Forward CV
# =============================================================================
def demonstrate_walk_forward_cv():
"""
Demonstrate walk-forward CV with gap enforcement.
"""
print("=" * 70)
print("TEMPORALCV: Walk-Forward Cross-Validation")
print("=" * 70)
# Load data
series, horizon, source = load_forecasting_data()
print(f"\nData source: {source}")
print(f"Series length: {len(series)}")
print(f"Forecast horizon: {horizon} steps")
# Create features
X, y = create_lagged_features(series, n_lags=12)
print(f"Feature matrix: {X.shape}")
# =========================================================================
# Part 1: Basic Walk-Forward CV
# =========================================================================
print("\n" + "=" * 70)
print("PART 1: Basic Walk-Forward CV (Expanding Window)")
print("=" * 70)
cv_expanding = WalkForwardCV(
n_splits=5,
window_type="expanding",
extra_gap=0, # No extra gap (for single-step)
test_size=12, # Test on 12 observations per fold
)
print(f"\nCV Configuration: {cv_expanding}")
print("\nSplit Structure:")
print("-" * 60)
for info in cv_expanding.get_split_info(X):
print(
f" Split {info.split_idx}: "
f"Train [{info.train_start:3d}-{info.train_end:3d}] ({info.train_size:3d} samples) | "
f"Gap: {info.gap:2d} | "
f"Test [{info.test_start:3d}-{info.test_end:3d}] ({info.test_size:2d} samples)"
)
# Evaluate model
scores = []
for train_idx, test_idx in cv_expanding.split(X):
model = Ridge(alpha=1.0)
model.fit(X[train_idx], y[train_idx])
preds = model.predict(X[test_idx])
mae = mean_absolute_error(y[test_idx], preds)
scores.append(mae)
print(f"\nCV Scores (MAE): {[f'{s:.2f}' for s in scores]}")
print(f"Mean MAE: {np.mean(scores):.2f} (+/- {np.std(scores):.2f})")
# =========================================================================
# Part 2: Gap Enforcement for h-Step Forecasting
# =========================================================================
print("\n" + "=" * 70)
print("PART 2: Gap Enforcement for Multi-Step Forecasting")
print("=" * 70)
print(f"\nProblem: Forecasting {horizon} steps ahead (h={horizon})")
print("Without gap enforcement, training targets leak test information!")
# Demonstrate the issue
print("\n--- WITHOUT Gap (WRONG for h-step) ---")
cv_no_gap = WalkForwardCV(n_splits=3, extra_gap=0, test_size=horizon)
for info in cv_no_gap.get_split_info(X):
# Check temporal boundary
result = gate_temporal_boundary(
train_end_idx=info.train_end,
test_start_idx=info.test_start,
horizon=horizon,
extra_gap=0,
)
status = "OK" if result.status.value == "PASS" else "LEAKAGE!"
print(
f" Split {info.split_idx}: "
f"Train ends at {info.train_end}, Test starts at {info.test_start}, "
f"Gap={info.gap} → {status}"
)
print("\n--- WITH Gap >= Horizon (CORRECT) ---")
cv_with_gap = WalkForwardCV(n_splits=3, horizon=horizon, extra_gap=0, test_size=horizon)
for info in cv_with_gap.get_split_info(X):
result = gate_temporal_boundary(
train_end_idx=info.train_end,
test_start_idx=info.test_start,
horizon=horizon,
extra_gap=0, # We already have horizon set in CV
)
status = "OK" if result.status.value == "PASS" else "LEAKAGE!"
print(
f" Split {info.split_idx}: "
f"Train ends at {info.train_end}, Test starts at {info.test_start}, "
f"Gap={info.gap} → {status}"
)
# =========================================================================
# Part 3: Expanding vs Sliding Window
# =========================================================================
print("\n" + "=" * 70)
print("PART 3: Expanding vs Sliding Window Comparison")
print("=" * 70)
window_size = 60 # 5 years of monthly data
cv_expanding = WalkForwardCV(
n_splits=5,
window_type="expanding",
window_size=window_size, # Minimum initial size
extra_gap=0,
test_size=12,
)
cv_sliding = WalkForwardCV(
n_splits=5,
window_type="sliding",
window_size=window_size, # Fixed size
extra_gap=0,
test_size=12,
)
print(f"\nWindow size: {window_size} observations")
print("\n--- Expanding Window ---")
print("Training set grows over time (uses all historical data)")
expanding_scores = []
for info in cv_expanding.get_split_info(X):
print(f" Split {info.split_idx}: Train size = {info.train_size}")
for train_idx, test_idx in cv_expanding.split(X):
model = Ridge(alpha=1.0)
model.fit(X[train_idx], y[train_idx])
preds = model.predict(X[test_idx])
expanding_scores.append(mean_absolute_error(y[test_idx], preds))
print(f" Mean MAE: {np.mean(expanding_scores):.2f}")
print("\n--- Sliding Window ---")
print("Training set is fixed size (adapts to regime changes)")
sliding_scores = []
for info in cv_sliding.get_split_info(X):
print(f" Split {info.split_idx}: Train size = {info.train_size}")
for train_idx, test_idx in cv_sliding.split(X):
model = Ridge(alpha=1.0)
model.fit(X[train_idx], y[train_idx])
preds = model.predict(X[test_idx])
sliding_scores.append(mean_absolute_error(y[test_idx], preds))
print(f" Mean MAE: {np.mean(sliding_scores):.2f}")
print("\n--- Comparison ---")
print(f" Expanding window MAE: {np.mean(expanding_scores):.2f}")
print(f" Sliding window MAE: {np.mean(sliding_scores):.2f}")
if np.mean(expanding_scores) < np.mean(sliding_scores):
print(" → Expanding window performs better (more data helps)")
else:
print(" → Sliding window performs better (older data may hurt)")
# =========================================================================
# Part 4: sklearn Integration
# =========================================================================
print("\n" + "=" * 70)
print("PART 4: sklearn Integration")
print("=" * 70)
print("\nWalkForwardCV is sklearn-compatible:")
print(" ✓ BaseCrossValidator subclass")
print(" ✓ Works with cross_val_score, GridSearchCV, etc.")
print(" ✓ Provides get_n_splits(), split(), __repr__")
print("\nExample with cross_val_score:")
print(
"""
from sklearn.model_selection import cross_val_score
from temporalcv import WalkForwardCV
cv = WalkForwardCV(n_splits=5, horizon=12, extra_gap=0)
scores = cross_val_score(model, X, y, cv=cv, scoring='neg_mean_absolute_error')
"""
)
# =========================================================================
# Key Takeaways
# =========================================================================
print("\n" + "=" * 70)
print("KEY TAKEAWAYS")
print("=" * 70)
print(
"""
1. ALWAYS use walk-forward CV for time-series (not random splits!)
- Temporal ordering must be preserved
- Training set must come before test set chronologically
2. SET horizon=h for h-step forecasting (extra_gap optional for safety margin)
- For 12-month ahead forecasts, use horizon=12, extra_gap=0 (minimum safe)
- Add extra_gap > 0 for additional temporal separation if desired
3. CHOOSE window type based on your data:
- Expanding: Use all history (good for stable processes)
- Sliding: Fixed window (good for regime changes, concept drift)
4. USE get_split_info() to debug and visualize splits
- See exactly what data is in train vs test
- Verify gaps are correct before training
5. INTEGRATE with sklearn ecosystem
- cross_val_score, GridSearchCV, RandomizedSearchCV all work
- Drop-in replacement for TimeSeriesSplit with better gap handling
"""
)
def visualize_walk_forward_cv():
"""
Visualize walk-forward CV using temporalcv.viz module.
"""
import matplotlib.pyplot as plt
# Load data and create features
series, horizon, _ = load_forecasting_data()
X, y = create_lagged_features(series, n_lags=12)
# %%
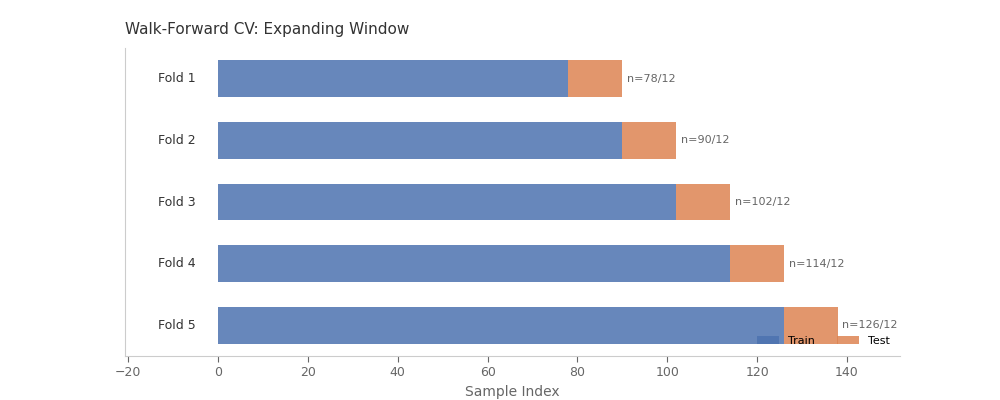
# Walk-Forward CV Fold Structure
# -------------------------------
# This visualization shows how WalkForwardCV preserves temporal ordering:
# training data (blue) always precedes the gap (red) and test data (orange).
# Create expanding window CV
cv = WalkForwardCV(
n_splits=5,
window_type="expanding",
extra_gap=0,
test_size=12,
)
# Use CVFoldsDisplay for Tufte-styled visualization
display = CVFoldsDisplay.from_cv(cv, X, y)
display.plot(title="Walk-Forward CV: Expanding Window")
plt.show()
# %%
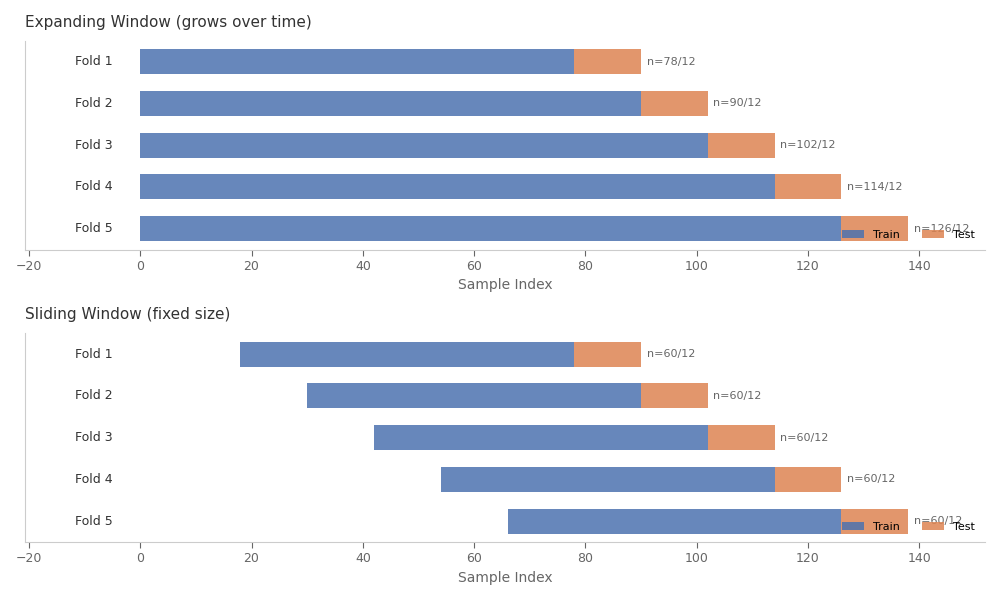
# Expanding vs Sliding Window Comparison
# --------------------------------------
# Expanding windows grow over time (using all history),
# while sliding windows maintain fixed size.
fig, axes = plt.subplots(2, 1, figsize=(10, 6))
# Expanding window
cv_expanding = WalkForwardCV(n_splits=5, window_type="expanding", window_size=60, test_size=12)
CVFoldsDisplay.from_cv(cv_expanding, X).plot(
ax=axes[0], title="Expanding Window (grows over time)"
)
# Sliding window
cv_sliding = WalkForwardCV(n_splits=5, window_type="sliding", window_size=60, test_size=12)
CVFoldsDisplay.from_cv(cv_sliding, X).plot(ax=axes[1], title="Sliding Window (fixed size)")
plt.tight_layout()
plt.show()
if __name__ == "__main__":
demonstrate_walk_forward_cv()
visualize_walk_forward_cv()