Note
Go to the end to download the full example code.
Example 17: FAILURE CASE — Threshold Leakage¶
Real-World Failure: Classification Threshold Computed on Full Data¶
A subtle but devastating bug: computing the optimal classification threshold (e.g., for binary classification) on the FULL dataset before splitting into train/test.
This leaks information because: 1. The threshold is optimized using test labels 2. The model’s predictions are then evaluated against this same test set 3. Performance is artificially inflated
Common scenarios: - ROC threshold optimization - Precision-recall threshold tuning - Quantile-based regime classification - Anomaly detection thresholds
This example demonstrates: 1. How threshold leakage inflates accuracy 2. How to detect it with suspicious improvement gates 3. The correct approach: threshold from training data only
Key Concepts¶
Threshold leakage: Using test labels to optimize classification cutoff
Proper threshold selection: Based only on training/validation data
gate_suspicious_improvement: Flags unrealistic accuracy gains
from __future__ import annotations
import numpy as np
import pandas as pd
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, f1_score, roc_curve
# temporalcv imports
from temporalcv.gates import gate_suspicious_improvement
from temporalcv.viz import MetricComparisonDisplay
# =============================================================================
# PART 1: Generate Time Series Classification Data
# =============================================================================
def generate_regime_data(
n_samples: int = 500,
prob_high: float = 0.3,
ar_coef: float = 0.7,
noise_std: float = 0.5,
seed: int = 42,
) -> pd.DataFrame:
"""
Generate time series with binary regime labels.
Simulates a market regime scenario:
- HIGH regime: Higher volatility, negative returns
- LOW regime: Lower volatility, positive returns
The regime depends on lagged features, making prediction possible.
Parameters
----------
n_samples : int
Number of samples.
prob_high : float
Unconditional probability of HIGH regime.
ar_coef : float
Autoregressive coefficient for features.
noise_std : float
Noise standard deviation.
seed : int
Random seed.
Returns
-------
pd.DataFrame
DataFrame with features and binary regime labels.
"""
rng = np.random.default_rng(seed)
# Generate AR(1) feature process
x1 = np.zeros(n_samples)
x1[0] = rng.normal(0, noise_std)
for t in range(1, n_samples):
x1[t] = ar_coef * x1[t - 1] + rng.normal(0, noise_std)
# Generate second feature
x2 = np.zeros(n_samples)
x2[0] = rng.normal(0, noise_std)
for t in range(1, n_samples):
x2[t] = 0.5 * x2[t - 1] + 0.3 * x1[t - 1] + rng.normal(0, noise_std)
# Generate regime based on lagged features
# HIGH regime when x1_lag + x2_lag > threshold
combined_signal = x1 + 0.5 * x2
regime_prob = 1 / (1 + np.exp(-combined_signal)) # Sigmoid
regime = (rng.random(n_samples) < regime_prob).astype(int)
# Create DataFrame
df = pd.DataFrame(
{
"regime": regime, # 0=LOW, 1=HIGH
"x1": x1,
"x2": x2,
}
)
# Add lagged features (strictly causal)
df["x1_lag1"] = df["x1"].shift(1)
df["x2_lag1"] = df["x2"].shift(1)
df["x1_lag2"] = df["x1"].shift(2)
df.index = pd.date_range("2020-01-01", periods=n_samples, freq="D")
df = df.dropna()
return df
print("=" * 70)
print("EXAMPLE 17: FAILURE CASE — THRESHOLD LEAKAGE")
print("=" * 70)
# Generate data
df = generate_regime_data(n_samples=500, seed=42)
print(f"\n📊 Generated regime classification data: {len(df)} samples")
print(f" Regime distribution: {dict(pd.Series(df['regime']).value_counts())}")
print(f" HIGH regime rate: {df['regime'].mean() * 100:.1f}%")
# =============================================================================
# PART 2: The Problem — Threshold from Full Data
# =============================================================================
print("\n" + "=" * 70)
print("PART 2: THE PROBLEM — THRESHOLD FROM FULL DATA")
print("=" * 70)
print(
"""
A common workflow for probability-based classification:
1. Train model on training data
2. Get probability predictions on ALL data
3. Find optimal threshold using ROC curve on ALL data ← BUG!
4. Apply threshold to test data
5. Report accuracy
Step 3 is the problem: the threshold is tuned using test labels,
then the model is evaluated on the same test set.
"""
)
# =============================================================================
# PART 3: WRONG Approach — Threshold from Full Dataset
# =============================================================================
print("\n" + "=" * 70)
print("PART 3: WRONG APPROACH — THRESHOLD FROM FULL DATASET")
print("=" * 70)
# Prepare data
feature_cols = ["x1_lag1", "x2_lag1", "x1_lag2"]
X = df[feature_cols].values
y = df["regime"].values
# Split
split_idx = int(len(df) * 0.7)
X_train, X_test = X[:split_idx], X[split_idx:]
y_train, y_test = y[:split_idx], y[split_idx:]
# Train model
model = LogisticRegression(random_state=42)
model.fit(X_train, y_train)
# Get probabilities on FULL dataset (for threshold optimization)
y_prob_full = model.predict_proba(X)[:, 1] # Probability of class 1
# WRONG: Find optimal threshold using FULL data (including test!)
fpr, tpr, thresholds = roc_curve(y, y_prob_full)
# Find threshold that maximizes Youden's J (TPR - FPR)
j_scores = tpr - fpr
optimal_idx = np.argmax(j_scores)
threshold_wrong = thresholds[optimal_idx]
print("❌ WRONG: Threshold computed on FULL data")
print(f" Optimal threshold (Youden's J): {threshold_wrong:.4f}")
print(" This threshold was tuned using test labels!")
# Apply threshold to test data
y_prob_test = model.predict_proba(X_test)[:, 1]
y_pred_wrong = (y_prob_test >= threshold_wrong).astype(int)
# Evaluate
acc_wrong = accuracy_score(y_test, y_pred_wrong)
f1_wrong = f1_score(y_test, y_pred_wrong)
print(f"\n Test Accuracy: {acc_wrong * 100:.1f}%")
print(f" Test F1 Score: {f1_wrong:.3f}")
print(" These metrics are INFLATED due to threshold leakage!")
# =============================================================================
# PART 4: CORRECT Approach — Threshold from Training Data Only
# =============================================================================
print("\n" + "=" * 70)
print("PART 4: CORRECT APPROACH — THRESHOLD FROM TRAINING DATA ONLY")
print("=" * 70)
print(
"""
The correct workflow:
1. Train model on training data
2. Get probability predictions on TRAINING data only
3. Find optimal threshold using ROC curve on TRAINING data
4. Apply threshold to test data
5. Report accuracy
Now the threshold never sees test labels.
"""
)
# Get probabilities on TRAINING data only
y_prob_train = model.predict_proba(X_train)[:, 1]
# CORRECT: Find optimal threshold using TRAINING data only
fpr_train, tpr_train, thresholds_train = roc_curve(y_train, y_prob_train)
j_scores_train = tpr_train - fpr_train
optimal_idx_train = np.argmax(j_scores_train)
threshold_correct = thresholds_train[optimal_idx_train]
print("✅ CORRECT: Threshold computed on TRAINING data only")
print(f" Optimal threshold (Youden's J): {threshold_correct:.4f}")
# Apply threshold to test data
y_pred_correct = (y_prob_test >= threshold_correct).astype(int)
# Evaluate
acc_correct = accuracy_score(y_test, y_pred_correct)
f1_correct = f1_score(y_test, y_pred_correct)
print(f"\n Test Accuracy: {acc_correct * 100:.1f}%")
print(f" Test F1 Score: {f1_correct:.3f}")
# =============================================================================
# PART 5: Comparing Results
# =============================================================================
print("\n" + "=" * 70)
print("PART 5: COMPARING RESULTS")
print("=" * 70)
# Baseline: default 0.5 threshold
y_pred_default = (y_prob_test >= 0.5).astype(int)
acc_default = accuracy_score(y_test, y_pred_default)
f1_default = f1_score(y_test, y_pred_default)
print("\n📊 Side-by-Side Comparison:")
print("-" * 70)
print(f"{'Method':<30} {'Threshold':<12} {'Accuracy':<12} {'F1 Score':<12}")
print("-" * 70)
print(f"{'Default (0.5)':<30} {0.5:<12.4f} {acc_default * 100:<12.1f}% {f1_default:<12.3f}")
print(
f"{'WRONG (full data)':<30} {threshold_wrong:<12.4f} {acc_wrong * 100:<12.1f}% {f1_wrong:<12.3f}"
)
print(
f"{'CORRECT (train only)':<30} {threshold_correct:<12.4f} {acc_correct * 100:<12.1f}% {f1_correct:<12.3f}"
)
print("-" * 70)
# Highlight the issue
if acc_wrong > acc_correct:
inflation = (acc_wrong - acc_correct) / acc_correct * 100
print(f"\n⚠️ WRONG approach shows {inflation:.1f}% higher accuracy!")
print(" This inflation is FAKE — it's due to threshold leakage.")
# =============================================================================
# PART 6: Detecting with Validation Gates
# =============================================================================
print("\n" + "=" * 70)
print("PART 6: DETECTING WITH VALIDATION GATES")
print("=" * 70)
print(
"""
gate_suspicious_improvement() can flag when a model's accuracy gain
over baseline is unrealistically high.
For classification, a naive baseline might be:
- Always predict majority class
- Random guessing
- A simple rule-based classifier
"""
)
# Baseline: majority class prediction
majority_class = int(y_train.mean() >= 0.5)
y_pred_baseline = np.full_like(y_test, majority_class)
acc_baseline = accuracy_score(y_test, y_pred_baseline)
print("\n📊 Baseline: Always predict majority class")
print(f" Majority class: {majority_class}")
print(f" Baseline accuracy: {acc_baseline * 100:.1f}%")
# Check WRONG approach
improvement_wrong = (acc_wrong - acc_baseline) / acc_baseline
gate_wrong = gate_suspicious_improvement(
model_metric=1 - acc_wrong, # Lower is better for error rate
baseline_metric=1 - acc_baseline,
threshold=0.40, # HALT if >40% improvement over baseline
warn_threshold=0.25,
)
print("\n🔍 Gate check for WRONG approach:")
print(f" Improvement over baseline: {improvement_wrong * 100:.1f}%")
print(f" Status: {gate_wrong.status}")
# Check CORRECT approach
improvement_correct = (acc_correct - acc_baseline) / acc_baseline
gate_correct = gate_suspicious_improvement(
model_metric=1 - acc_correct,
baseline_metric=1 - acc_baseline,
threshold=0.40,
warn_threshold=0.25,
)
print("\n🔍 Gate check for CORRECT approach:")
print(f" Improvement over baseline: {improvement_correct * 100:.1f}%")
print(f" Status: {gate_correct.status}")
# =============================================================================
# PART 7: Other Scenarios Where This Bug Appears
# =============================================================================
print("\n" + "=" * 70)
print("PART 7: OTHER SCENARIOS WHERE THIS BUG APPEARS")
print("=" * 70)
print(
"""
Threshold leakage can occur in many places:
1. BINARY CLASSIFICATION THRESHOLD
- ROC curve threshold optimization
- Precision-recall curve threshold
- Cost-sensitive threshold tuning
2. ANOMALY DETECTION
- Percentile-based anomaly threshold (top 5% = anomaly)
- If computed on full data, test anomalies influence threshold
3. REGIME CLASSIFICATION
- "HIGH volatility" = above 75th percentile
- If percentile computed on full data, it includes test
4. QUANTILE REGRESSION
- Predicting median or other quantiles
- If quantile targets computed on full data, leakage
5. NORMALIZATION
- StandardScaler fit on full data
- Test mean/std leak into training features
6. FEATURE SELECTION
- Selecting features based on correlation with target
- If done on full data, test correlations leak
"""
)
# =============================================================================
# PART 8: Key Takeaways
# =============================================================================
print("\n" + "=" * 70)
print("PART 8: KEY TAKEAWAYS")
print("=" * 70)
print(
"""
1. THRESHOLDS MUST COME FROM TRAINING DATA ONLY
- Never use test labels to tune classification threshold
- This is true for any hyperparameter/decision boundary
2. THE BUG IS SUBTLE
- Code looks correct: model.fit(X_train), then threshold on ROC
- The ROC is computed on full data — that's the leak
- No error messages, just silently inflated metrics
3. WALK-FORWARD CV HELPS
- Each fold should have its own threshold from train portion
- Threshold at deployment = threshold from full training set
- Never retune threshold using production data
4. VALIDATION GATES CATCH THIS
- Unrealistically high accuracy flags possible leakage
- Compare to a genuine baseline (majority class, random)
- If you're "beating" baseline by 50%+, investigate
5. CHECK ALL PREPROCESSING STEPS
- Any step that uses target information is suspect
- Normalization, feature selection, threshold tuning
- If it uses test data, it's leakage
The pattern: NOTHING computed from the training pipeline should
see test labels, directly or indirectly.
"""
)
print("\n" + "=" * 70)
print("Example 17 complete.")
print("=" * 70)
======================================================================
EXAMPLE 17: FAILURE CASE — THRESHOLD LEAKAGE
======================================================================
📊 Generated regime classification data: 498 samples
Regime distribution: {1: np.int64(249), 0: np.int64(249)}
HIGH regime rate: 50.0%
======================================================================
PART 2: THE PROBLEM — THRESHOLD FROM FULL DATA
======================================================================
A common workflow for probability-based classification:
1. Train model on training data
2. Get probability predictions on ALL data
3. Find optimal threshold using ROC curve on ALL data ← BUG!
4. Apply threshold to test data
5. Report accuracy
Step 3 is the problem: the threshold is tuned using test labels,
then the model is evaluated on the same test set.
======================================================================
PART 3: WRONG APPROACH — THRESHOLD FROM FULL DATASET
======================================================================
❌ WRONG: Threshold computed on FULL data
Optimal threshold (Youden's J): 0.5014
This threshold was tuned using test labels!
Test Accuracy: 63.3%
Test F1 Score: 0.654
These metrics are INFLATED due to threshold leakage!
======================================================================
PART 4: CORRECT APPROACH — THRESHOLD FROM TRAINING DATA ONLY
======================================================================
The correct workflow:
1. Train model on training data
2. Get probability predictions on TRAINING data only
3. Find optimal threshold using ROC curve on TRAINING data
4. Apply threshold to test data
5. Report accuracy
Now the threshold never sees test labels.
✅ CORRECT: Threshold computed on TRAINING data only
Optimal threshold (Youden's J): 0.4597
Test Accuracy: 58.7%
Test F1 Score: 0.656
======================================================================
PART 5: COMPARING RESULTS
======================================================================
📊 Side-by-Side Comparison:
----------------------------------------------------------------------
Method Threshold Accuracy F1 Score
----------------------------------------------------------------------
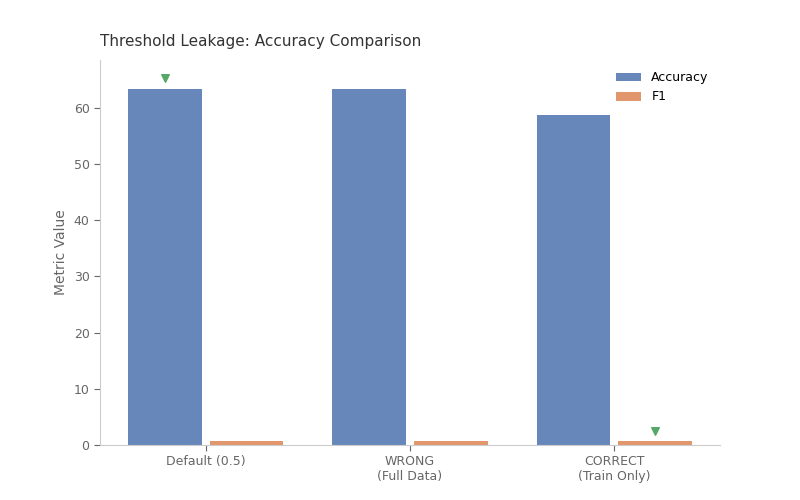
Default (0.5) 0.5000 63.3 % 0.654
WRONG (full data) 0.5014 63.3 % 0.654
CORRECT (train only) 0.4597 58.7 % 0.656
----------------------------------------------------------------------
⚠️ WRONG approach shows 8.0% higher accuracy!
This inflation is FAKE — it's due to threshold leakage.
======================================================================
PART 6: DETECTING WITH VALIDATION GATES
======================================================================
gate_suspicious_improvement() can flag when a model's accuracy gain
over baseline is unrealistically high.
For classification, a naive baseline might be:
- Always predict majority class
- Random guessing
- A simple rule-based classifier
📊 Baseline: Always predict majority class
Majority class: 1
Baseline accuracy: 47.3%
🔍 Gate check for WRONG approach:
Improvement over baseline: 33.8%
Status: GateStatus.WARN
🔍 Gate check for CORRECT approach:
Improvement over baseline: 23.9%
Status: GateStatus.PASS
======================================================================
PART 7: OTHER SCENARIOS WHERE THIS BUG APPEARS
======================================================================
Threshold leakage can occur in many places:
1. BINARY CLASSIFICATION THRESHOLD
- ROC curve threshold optimization
- Precision-recall curve threshold
- Cost-sensitive threshold tuning
2. ANOMALY DETECTION
- Percentile-based anomaly threshold (top 5% = anomaly)
- If computed on full data, test anomalies influence threshold
3. REGIME CLASSIFICATION
- "HIGH volatility" = above 75th percentile
- If percentile computed on full data, it includes test
4. QUANTILE REGRESSION
- Predicting median or other quantiles
- If quantile targets computed on full data, leakage
5. NORMALIZATION
- StandardScaler fit on full data
- Test mean/std leak into training features
6. FEATURE SELECTION
- Selecting features based on correlation with target
- If done on full data, test correlations leak
======================================================================
PART 8: KEY TAKEAWAYS
======================================================================
1. THRESHOLDS MUST COME FROM TRAINING DATA ONLY
- Never use test labels to tune classification threshold
- This is true for any hyperparameter/decision boundary
2. THE BUG IS SUBTLE
- Code looks correct: model.fit(X_train), then threshold on ROC
- The ROC is computed on full data — that's the leak
- No error messages, just silently inflated metrics
3. WALK-FORWARD CV HELPS
- Each fold should have its own threshold from train portion
- Threshold at deployment = threshold from full training set
- Never retune threshold using production data
4. VALIDATION GATES CATCH THIS
- Unrealistically high accuracy flags possible leakage
- Compare to a genuine baseline (majority class, random)
- If you're "beating" baseline by 50%+, investigate
5. CHECK ALL PREPROCESSING STEPS
- Any step that uses target information is suspect
- Normalization, feature selection, threshold tuning
- If it uses test data, it's leakage
The pattern: NOTHING computed from the training pipeline should
see test labels, directly or indirectly.
======================================================================
Example 17 complete.
======================================================================
Threshold Leakage Impact¶
Comparing accuracy and F1 scores across three approaches: - Default 0.5 threshold - WRONG: Threshold from full data (leaks test info) - CORRECT: Threshold from training data only
import matplotlib.pyplot as plt
results = {
"Default (0.5)": {"Accuracy": acc_default * 100, "F1": f1_default},
"WRONG\n(Full Data)": {"Accuracy": acc_wrong * 100, "F1": f1_wrong},
"CORRECT\n(Train Only)": {"Accuracy": acc_correct * 100, "F1": f1_correct},
}
display = MetricComparisonDisplay.from_dict(
results, lower_is_better={"Accuracy": False, "F1": False}
)
display.plot(title="Threshold Leakage: Accuracy Comparison", show_values=True)
plt.show()