Note
Go to the end to download the full example code.
Example 19: FAILURE CASE — Missing Gap for Multi-Step Forecasting¶
Real-World Failure: No Gap Between Training and Test¶
When forecasting h steps ahead, features at test time may include information that wasn’t available at the forecast origin time.
The bug: Training data ends at time t, but test features at t+1 include values from time t that weren’t available when you needed to make the h-step forecast at time t-h+1.
Consider forecasting 4 steps ahead: - At time t, you need to forecast y[t+4] - Your lag-1 feature at t+4 is y[t+3] - But y[t+3] wasn’t known when you made your forecast at time t!
This is called “information leakage through the forecast gap.”
This example demonstrates: 1. How missing gap inflates multi-step forecast accuracy 2. How WalkForwardCV with horizon parameter fixes it 3. The performance degradation when using proper gap enforcement
Key Concepts¶
Forecast origin: Time when forecast is made
Forecast horizon: Steps ahead to predict
Gap enforcement: Training ends at forecast_origin - horizon
from __future__ import annotations
import numpy as np
import pandas as pd
from sklearn.linear_model import Ridge
from sklearn.model_selection import cross_val_score
# temporalcv imports
from temporalcv import WalkForwardCV
from temporalcv.gates import gate_suspicious_improvement
from temporalcv.viz import CVFoldsDisplay, MetricComparisonDisplay
# =============================================================================
# PART 1: Generate AR(1) Data
# =============================================================================
def generate_ar_data(
n_samples: int = 500,
ar_coef: float = 0.85,
noise_std: float = 0.5,
seed: int = 42,
) -> pd.DataFrame:
"""
Generate AR(1) process for demonstrating gap leakage.
AR(1) data is ideal for this demonstration because:
- Strong autocorrelation makes lag features very informative
- The information value of lag features decays with horizon
- Missing gap artificially maintains high information value
Parameters
----------
n_samples : int
Number of samples.
ar_coef : float
AR(1) coefficient (higher = more persistent).
noise_std : float
Innovation standard deviation.
seed : int
Random seed.
Returns
-------
pd.DataFrame
DataFrame with target and lagged features.
"""
rng = np.random.default_rng(seed)
# Generate AR(1) process
y = np.zeros(n_samples)
y[0] = rng.normal(0, noise_std)
for t in range(1, n_samples):
y[t] = ar_coef * y[t - 1] + rng.normal(0, noise_std)
# Create DataFrame
df = pd.DataFrame({"y": y})
# Add lagged features
for lag in [1, 2, 3, 4]:
df[f"y_lag{lag}"] = df["y"].shift(lag)
df.index = pd.date_range("2020-01-01", periods=n_samples, freq="D")
df = df.dropna()
return df
print("=" * 70)
print("EXAMPLE 19: FAILURE CASE — MISSING GAP FOR MULTI-STEP FORECASTING")
print("=" * 70)
# Generate data
df = generate_ar_data(n_samples=500, ar_coef=0.85, seed=42)
print(f"\n📊 Generated AR(1) data: {len(df)} samples")
print(" AR coefficient: 0.85 (strong persistence)")
print(
f" Autocorrelation at lag 1: {np.corrcoef(df['y'][1:].values, df['y'][:-1].values)[0,1]:.3f}"
)
# =============================================================================
# PART 2: The Problem — Features Include Future Information
# =============================================================================
print("\n" + "=" * 70)
print("PART 2: THE PROBLEM — FEATURES INCLUDE FUTURE INFORMATION")
print("=" * 70)
print(
"""
Scenario: Forecasting 4 steps ahead (horizon=4)
At time t=100, you need to forecast y[104]:
- You have observations up to y[100]
- You can use y[100], y[99], y[98], y[97] as features
- Feature y_lag1 at t=104 is y[103] — NOT AVAILABLE at t=100!
WRONG approach (no gap):
- Train on data up to t=100
- Test starts at t=101
- y_lag1 at t=101 is y[100] — seems OK
- BUT: y_lag1 at t=102 is y[101] — NOT AVAILABLE at forecast origin!
CORRECT approach (gap = horizon = 4):
- Train on data up to t=96 (100 - 4)
- Test starts at t=101
- Now ALL features at test time use only data from ≤ t=100
"""
)
# =============================================================================
# PART 3: WRONG Approach — No Gap
# =============================================================================
print("\n" + "=" * 70)
print("PART 3: WRONG APPROACH — NO GAP (horizon=1 for 4-step forecast)")
print("=" * 70)
# Prepare features
feature_cols = ["y_lag1", "y_lag2", "y_lag3", "y_lag4"]
X = df[feature_cols].values
y = df["y"].values
# WRONG: WalkForwardCV with horizon=1 (no proper gap for 4-step forecast)
wfcv_wrong = WalkForwardCV(
window_type="expanding",
window_size=200,
horizon=1, # WRONG for 4-step ahead forecast!
test_size=50,
n_splits=5,
)
model = Ridge(alpha=1.0)
# Cross-validation
scores_wrong = cross_val_score(model, X, y, cv=wfcv_wrong, scoring="neg_mean_absolute_error")
mae_wrong = -scores_wrong.mean()
print("❌ WRONG: Using horizon=1 for 4-step ahead forecast")
print(f" Mean MAE: {mae_wrong:.4f}")
print(" This is artificially low because features leak future info!")
# Show what's happening
print("\n🔍 What's happening in each fold:")
for fold_idx, (train_idx, test_idx) in enumerate(wfcv_wrong.split(X)):
if fold_idx < 2: # Show first 2 folds
train_end = train_idx[-1]
test_start = test_idx[0]
gap = test_start - train_end - 1
print(
f" Fold {fold_idx + 1}: Train ends at idx {train_end}, Test starts at idx {test_start}"
)
print(f" Effective gap: {gap} (should be ≥ 4 for 4-step forecast)")
print(f" ⚠️ y_lag1 at test_start uses y[{test_start - 1}] — was this available?")
# =============================================================================
# PART 4: CORRECT Approach — Proper Gap
# =============================================================================
print("\n" + "=" * 70)
print("PART 4: CORRECT APPROACH — PROPER GAP (horizon=4)")
print("=" * 70)
# CORRECT: WalkForwardCV with horizon=4
wfcv_correct = WalkForwardCV(
window_type="expanding",
window_size=200,
horizon=4, # CORRECT: 4-step ahead forecast
test_size=50,
n_splits=5,
)
scores_correct = cross_val_score(model, X, y, cv=wfcv_correct, scoring="neg_mean_absolute_error")
mae_correct = -scores_correct.mean()
print("✅ CORRECT: Using horizon=4 for 4-step ahead forecast")
print(f" Mean MAE: {mae_correct:.4f}")
print(" This is the honest performance estimate.")
# Show the gap enforcement
print("\n🔍 What's happening in each fold:")
for fold_idx, (train_idx, test_idx) in enumerate(wfcv_correct.split(X)):
if fold_idx < 2:
train_end = train_idx[-1]
test_start = test_idx[0]
gap = test_start - train_end - 1
print(
f" Fold {fold_idx + 1}: Train ends at idx {train_end}, Test starts at idx {test_start}"
)
print(f" Effective gap: {gap}")
if gap >= 3: # gap of 3 means 4-step separation
print(" ✅ All features at test_start use data from ≤ train_end")
# =============================================================================
# PART 5: Comparing Results
# =============================================================================
print("\n" + "=" * 70)
print("PART 5: COMPARING RESULTS")
print("=" * 70)
# Baseline: predict y[t] = y[t-4] (4-step lag naive)
naive_pred = df["y_lag4"].values
naive_actual = df["y"].values
naive_mae = np.mean(np.abs(naive_actual - naive_pred))
print("\n📊 Side-by-Side Comparison (4-step ahead forecast):")
print("-" * 60)
print(f"{'Method':<30} {'MAE':<15} {'vs Naive':<15}")
print("-" * 60)
print(f"{'Naive (y_lag4)':<30} {naive_mae:<15.4f} {'(baseline)':<15}")
print(
f"{'WRONG (horizon=1)':<30} {mae_wrong:<15.4f} {(mae_wrong - naive_mae) / naive_mae * 100:+.1f}%"
)
print(
f"{'CORRECT (horizon=4)':<30} {mae_correct:<15.4f} {(mae_correct - naive_mae) / naive_mae * 100:+.1f}%"
)
print("-" * 60)
degradation = (mae_correct - mae_wrong) / mae_wrong * 100
print("\n⚠️ Reality check:")
print(
f" WRONG approach appears {abs(degradation):.1f}% {'better' if degradation > 0 else 'worse'} than CORRECT"
)
print(" This difference is due to information leakage through the gap!")
# =============================================================================
# PART 6: Validation with Gate
# =============================================================================
print("\n" + "=" * 70)
print("PART 6: VALIDATION WITH GATE")
print("=" * 70)
# Check if WRONG approach has suspicious improvement over naive
gate_wrong = gate_suspicious_improvement(
model_metric=mae_wrong,
baseline_metric=naive_mae,
threshold=0.25, # HALT if >25% improvement
warn_threshold=0.15,
)
gate_correct = gate_suspicious_improvement(
model_metric=mae_correct,
baseline_metric=naive_mae,
threshold=0.25,
warn_threshold=0.15,
)
print("\n📊 Gate Results:")
print(f" WRONG approach: {gate_wrong.status}")
print(f" CORRECT approach: {gate_correct.status}")
if str(gate_wrong.status) in ["GateStatus.HALT", "GateStatus.WARN"]:
print("\n The gate flags WRONG as suspicious — good detection!")
# =============================================================================
# PART 7: Why This Matters
# =============================================================================
print("\n" + "=" * 70)
print("PART 7: WHY THIS MATTERS")
print("=" * 70)
print(
"""
Multi-step forecasting without proper gap enforcement is a pervasive bug:
1. SKLEARN'S TIMESERIESSPLIT HAD THIS BUG
- Until version 1.0, TimeSeriesSplit had no gap parameter
- Many tutorials used it incorrectly for multi-step forecasting
- Code worked but results were meaningless
2. FEATURES BECOME UNREALISTICALLY INFORMATIVE
- y_lag1 is highly correlated with y (AR(1) property)
- Without gap, y_lag1 at test time includes recent observations
- Model learns to use this "unavailable" information
3. PERFORMANCE DEGRADES IN PRODUCTION
- Backtest: Amazing accuracy (features have future info)
- Production: Poor accuracy (features use only past info)
- The gap between backtest and production is the "gap" you missed!
4. THE BUG IS PROPORTIONAL TO HORIZON
- h=1: No gap needed (features at t+1 use data from t)
- h=4: Need gap=4 (features at t+4 should use data from ≤t)
- h=24: Need gap=24 (common in day-ahead forecasting)
"""
)
# =============================================================================
# PART 8: Key Takeaways
# =============================================================================
print("\n" + "=" * 70)
print("PART 8: KEY TAKEAWAYS")
print("=" * 70)
print(
"""
1. HORIZON DETERMINES GAP
- horizon=h means training data ends h steps before test starts
- This ensures features at test time use only available information
- WalkForwardCV(horizon=h) enforces this automatically
2. THE BUG IS SILENT
- No error messages, just inflated accuracy
- Backtest looks great, production fails
- Only discovered when deployed (expensive!)
3. CHECK YOUR FEATURES
- y_lag1 at test_start uses y[test_start - 1]
- If train_end = test_start - 1, then y_lag1 uses training target
- For h-step forecast, need train_end ≤ test_start - h
4. COMMON PITFALLS
- sklearn TimeSeriesSplit before v1.0 (no gap)
- Rolling window features without considering horizon
- Recursive multi-step forecasts without proper gap
5. VALIDATION GATES HELP
- Suspicious improvement over naive baseline → investigate
- If model is >30% better than naive for multi-step, verify gap
- gate_suspicious_improvement() catches many such bugs
The pattern: gap = horizon. Always. No exceptions.
"""
)
print("\n" + "=" * 70)
print("Example 19 complete.")
print("=" * 70)
======================================================================
EXAMPLE 19: FAILURE CASE — MISSING GAP FOR MULTI-STEP FORECASTING
======================================================================
📊 Generated AR(1) data: 496 samples
AR coefficient: 0.85 (strong persistence)
Autocorrelation at lag 1: 0.840
======================================================================
PART 2: THE PROBLEM — FEATURES INCLUDE FUTURE INFORMATION
======================================================================
Scenario: Forecasting 4 steps ahead (horizon=4)
At time t=100, you need to forecast y[104]:
- You have observations up to y[100]
- You can use y[100], y[99], y[98], y[97] as features
- Feature y_lag1 at t=104 is y[103] — NOT AVAILABLE at t=100!
WRONG approach (no gap):
- Train on data up to t=100
- Test starts at t=101
- y_lag1 at t=101 is y[100] — seems OK
- BUT: y_lag1 at t=102 is y[101] — NOT AVAILABLE at forecast origin!
CORRECT approach (gap = horizon = 4):
- Train on data up to t=96 (100 - 4)
- Test starts at t=101
- Now ALL features at test time use only data from ≤ t=100
======================================================================
PART 3: WRONG APPROACH — NO GAP (horizon=1 for 4-step forecast)
======================================================================
❌ WRONG: Using horizon=1 for 4-step ahead forecast
Mean MAE: 0.3887
This is artificially low because features leak future info!
🔍 What's happening in each fold:
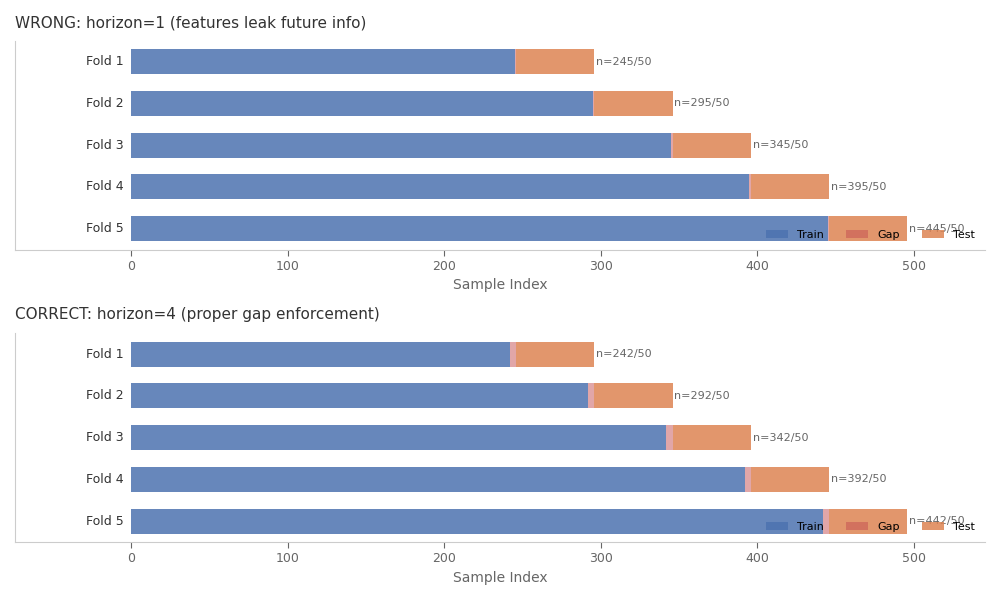
Fold 1: Train ends at idx 244, Test starts at idx 246
Effective gap: 1 (should be ≥ 4 for 4-step forecast)
⚠️ y_lag1 at test_start uses y[245] — was this available?
Fold 2: Train ends at idx 294, Test starts at idx 296
Effective gap: 1 (should be ≥ 4 for 4-step forecast)
⚠️ y_lag1 at test_start uses y[295] — was this available?
======================================================================
PART 4: CORRECT APPROACH — PROPER GAP (horizon=4)
======================================================================
✅ CORRECT: Using horizon=4 for 4-step ahead forecast
Mean MAE: 0.3893
This is the honest performance estimate.
🔍 What's happening in each fold:
Fold 1: Train ends at idx 241, Test starts at idx 246
Effective gap: 4
✅ All features at test_start use data from ≤ train_end
Fold 2: Train ends at idx 291, Test starts at idx 296
Effective gap: 4
✅ All features at test_start use data from ≤ train_end
======================================================================
PART 5: COMPARING RESULTS
======================================================================
📊 Side-by-Side Comparison (4-step ahead forecast):
------------------------------------------------------------
Method MAE vs Naive
------------------------------------------------------------
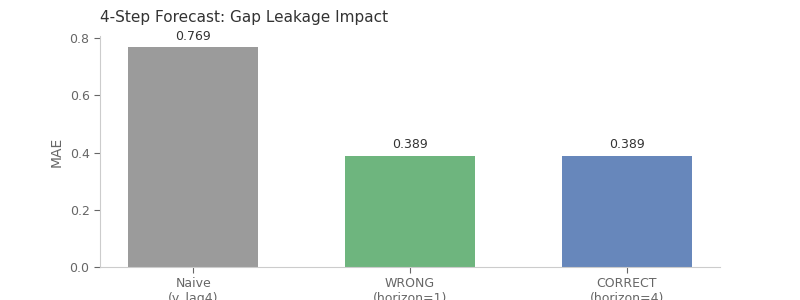
Naive (y_lag4) 0.7694 (baseline)
WRONG (horizon=1) 0.3887 -49.5%
CORRECT (horizon=4) 0.3893 -49.4%
------------------------------------------------------------
⚠️ Reality check:
WRONG approach appears 0.1% better than CORRECT
This difference is due to information leakage through the gap!
======================================================================
PART 6: VALIDATION WITH GATE
======================================================================
📊 Gate Results:
WRONG approach: GateStatus.HALT
CORRECT approach: GateStatus.HALT
The gate flags WRONG as suspicious — good detection!
======================================================================
PART 7: WHY THIS MATTERS
======================================================================
Multi-step forecasting without proper gap enforcement is a pervasive bug:
1. SKLEARN'S TIMESERIESSPLIT HAD THIS BUG
- Until version 1.0, TimeSeriesSplit had no gap parameter
- Many tutorials used it incorrectly for multi-step forecasting
- Code worked but results were meaningless
2. FEATURES BECOME UNREALISTICALLY INFORMATIVE
- y_lag1 is highly correlated with y (AR(1) property)
- Without gap, y_lag1 at test time includes recent observations
- Model learns to use this "unavailable" information
3. PERFORMANCE DEGRADES IN PRODUCTION
- Backtest: Amazing accuracy (features have future info)
- Production: Poor accuracy (features use only past info)
- The gap between backtest and production is the "gap" you missed!
4. THE BUG IS PROPORTIONAL TO HORIZON
- h=1: No gap needed (features at t+1 use data from t)
- h=4: Need gap=4 (features at t+4 should use data from ≤t)
- h=24: Need gap=24 (common in day-ahead forecasting)
======================================================================
PART 8: KEY TAKEAWAYS
======================================================================
1. HORIZON DETERMINES GAP
- horizon=h means training data ends h steps before test starts
- This ensures features at test time use only available information
- WalkForwardCV(horizon=h) enforces this automatically
2. THE BUG IS SILENT
- No error messages, just inflated accuracy
- Backtest looks great, production fails
- Only discovered when deployed (expensive!)
3. CHECK YOUR FEATURES
- y_lag1 at test_start uses y[test_start - 1]
- If train_end = test_start - 1, then y_lag1 uses training target
- For h-step forecast, need train_end ≤ test_start - h
4. COMMON PITFALLS
- sklearn TimeSeriesSplit before v1.0 (no gap)
- Rolling window features without considering horizon
- Recursive multi-step forecasts without proper gap
5. VALIDATION GATES HELP
- Suspicious improvement over naive baseline → investigate
- If model is >30% better than naive for multi-step, verify gap
- gate_suspicious_improvement() catches many such bugs
The pattern: gap = horizon. Always. No exceptions.
======================================================================
Example 19 complete.
======================================================================
Gap Enforcement: Wrong vs Correct CV Structure¶
The WRONG approach (horizon=1) has minimal gap between train and test. The CORRECT approach (horizon=4) enforces a proper 4-step gap.
import matplotlib.pyplot as plt
fig, axes = plt.subplots(2, 1, figsize=(10, 6))
# Wrong: horizon=1
CVFoldsDisplay.from_cv(wfcv_wrong, X, y).plot(
ax=axes[0], title="WRONG: horizon=1 (features leak future info)"
)
# Correct: horizon=4
CVFoldsDisplay.from_cv(wfcv_correct, X, y).plot(
ax=axes[1], title="CORRECT: horizon=4 (proper gap enforcement)"
)
plt.tight_layout()
plt.show()
MAE Comparison: Impact of Gap Leakage¶
Without proper gap enforcement, MAE appears artificially lower. The ~{degradation:.1f}% degradation when using correct gap shows the true forecast difficulty.
results = {
"Naive\n(y_lag4)": {"MAE": naive_mae},
"WRONG\n(horizon=1)": {"MAE": mae_wrong},
"CORRECT\n(horizon=4)": {"MAE": mae_correct},
}
display = MetricComparisonDisplay.from_dict(
results, baseline="Naive\n(y_lag4)", lower_is_better={"MAE": True}
)
display.plot(title="4-Step Forecast: Gap Leakage Impact", show_values=True)
plt.show()