Note
Go to the end to download the full example code.
Example 07: Nested Cross-Validation for Hyperparameter Tuning¶
Real-World Case Study: Avoiding Hyperparameter Leakage¶
When tuning hyperparameters on time series data, using the same data for both tuning and evaluation causes optimistic bias. The selected hyperparameters are “overfit” to the evaluation period.
Nested CV solves this by: - Inner loop: Tune hyperparameters - Outer loop: Evaluate generalization (unseen by inner loop)
This example shows proper nested CV for time series forecasting.
Key Concepts¶
Nested cross-validation structure
Why standard GridSearchCV fails for time series
Proper hyperparameter selection with temporal order
Comparing nested vs non-nested estimates
from __future__ import annotations
import warnings
from typing import Any
import numpy as np
from sklearn.base import BaseEstimator, clone
from sklearn.ensemble import GradientBoostingRegressor
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import GridSearchCV
# temporalcv imports
from temporalcv import WalkForwardCV
from temporalcv.viz import CVFoldsDisplay, MetricComparisonDisplay
warnings.filterwarnings("ignore", category=UserWarning)
# =============================================================================
# PART 1: Generate Synthetic Time Series Data
# =============================================================================
def generate_ar_series(
n: int = 500,
ar_coefs: list[float] | None = None,
noise_std: float = 1.0,
seed: int = 42,
) -> tuple[np.ndarray, np.ndarray]:
"""
Generate AR(p) time series with features.
Parameters
----------
n : int
Length of series.
ar_coefs : list of float
AR coefficients. Default is [0.6, 0.2] for AR(2).
noise_std : float
Standard deviation of innovations.
seed : int
Random seed.
Returns
-------
X : np.ndarray
Feature matrix (lagged values).
y : np.ndarray
Target values.
"""
if ar_coefs is None:
ar_coefs = [0.6, 0.2]
rng = np.random.default_rng(seed)
p = len(ar_coefs)
# Generate AR series
y_full = np.zeros(n + p)
y_full[:p] = rng.normal(0, noise_std, p)
for t in range(p, n + p):
y_full[t] = sum(c * y_full[t - i - 1] for i, c in enumerate(ar_coefs))
y_full[t] += rng.normal(0, noise_std)
y_full = y_full[p:] # Remove burn-in
# Create features (lagged values)
max_lag = 5
X = np.zeros((n - max_lag, max_lag))
for lag in range(1, max_lag + 1):
X[:, lag - 1] = y_full[max_lag - lag : n - lag]
y = y_full[max_lag:]
return X, y
print("=" * 70)
print("PART 1: Data Generation")
print("=" * 70)
X, y = generate_ar_series(n=500, ar_coefs=[0.6, 0.2], seed=42)
print(f"\nGenerated AR(2) series with {len(y)} observations")
print("Features: 5 lagged values")
print(f"Data shape: X={X.shape}, y={y.shape}")
# =============================================================================
# PART 2: The Problem - Hyperparameter Leakage
# =============================================================================
print("\n" + "=" * 70)
print("PART 2: The Problem - Hyperparameter Leakage")
print("=" * 70)
print(
"""
Standard approach (WRONG for time series):
1. Run GridSearchCV with KFold to find best hyperparameters
2. Report CV score as expected performance
Problems:
- Future data influences hyperparameter selection
- CV score is optimistically biased
- Selected hyperparameters may not generalize
The score from GridSearchCV is NOT a valid estimate of future performance.
It's contaminated by the hyperparameter selection process.
"""
)
# Demonstrate the problem
base_model = GradientBoostingRegressor(random_state=42)
param_grid = {
"n_estimators": [50, 100, 200],
"max_depth": [2, 3, 5],
"learning_rate": [0.05, 0.1, 0.2],
}
# WRONG: Using standard GridSearchCV
print("WRONG: Standard GridSearchCV with time series data")
from sklearn.model_selection import KFold
grid_search = GridSearchCV(
base_model,
param_grid,
cv=KFold(n_splits=5, shuffle=True),
scoring="neg_mean_squared_error",
n_jobs=-1,
)
grid_search.fit(X, y)
print(f"\n Best params: {grid_search.best_params_}")
print(f" GridSearchCV score: {np.sqrt(-grid_search.best_score_):.4f} RMSE")
print(" WARNING: This score is optimistically biased!")
# =============================================================================
# PART 3: Solution - Nested Time Series Cross-Validation
# =============================================================================
print("\n" + "=" * 70)
print("PART 3: Solution - Nested Cross-Validation")
print("=" * 70)
print(
"""
Nested CV structure:
OUTER LOOP (evaluation, never seen by inner loop):
Fold 1: Train [1-300] --> Test [301-400]
Fold 2: Train [1-400] --> Test [401-500]
INNER LOOP (hyperparameter tuning, within each outer train set):
Inner Fold 1: Train [1-150] --> Val [151-200]
Inner Fold 2: Train [1-200] --> Val [201-250]
Inner Fold 3: Train [1-250] --> Val [251-300]
The outer test sets are NEVER used for hyperparameter selection.
This gives an unbiased estimate of generalization performance.
"""
)
def nested_time_series_cv(
X: np.ndarray,
y: np.ndarray,
model: BaseEstimator,
param_grid: dict[str, list[Any]],
outer_cv: Any,
inner_cv_factory: Any,
verbose: bool = True,
) -> dict[str, Any]:
"""
Perform nested cross-validation for time series.
Parameters
----------
X : np.ndarray
Features.
y : np.ndarray
Target.
model : BaseEstimator
Base model to tune.
param_grid : dict
Hyperparameter grid.
outer_cv : cross-validator
Outer CV splitter (for evaluation).
inner_cv_factory : callable
Function that returns inner CV splitter given training data size.
verbose : bool
Print progress.
Returns
-------
dict
Results including scores and best params per fold.
"""
outer_scores = []
inner_best_scores = []
best_params_per_fold = []
for fold_idx, (outer_train_idx, outer_test_idx) in enumerate(outer_cv.split(X)):
if verbose:
print(f"\n Outer Fold {fold_idx + 1}:")
print(f" Train size: {len(outer_train_idx)}, Test size: {len(outer_test_idx)}")
X_outer_train = X[outer_train_idx]
y_outer_train = y[outer_train_idx]
X_outer_test = X[outer_test_idx]
y_outer_test = y[outer_test_idx]
# Inner CV for hyperparameter tuning
inner_cv = inner_cv_factory(len(outer_train_idx))
grid_search = GridSearchCV(
clone(model),
param_grid,
cv=inner_cv,
scoring="neg_mean_squared_error",
n_jobs=-1,
refit=True, # Refit on full outer train set with best params
)
grid_search.fit(X_outer_train, y_outer_train)
inner_best_scores.append(np.sqrt(-grid_search.best_score_))
best_params_per_fold.append(grid_search.best_params_)
if verbose:
print(f" Inner best params: {grid_search.best_params_}")
print(f" Inner best score: {np.sqrt(-grid_search.best_score_):.4f} RMSE")
# Evaluate on outer test set (never seen by inner loop)
y_pred = grid_search.predict(X_outer_test)
outer_rmse = np.sqrt(mean_squared_error(y_outer_test, y_pred))
outer_scores.append(outer_rmse)
if verbose:
print(f" Outer test score: {outer_rmse:.4f} RMSE")
return {
"outer_scores": outer_scores,
"inner_best_scores": inner_best_scores,
"best_params_per_fold": best_params_per_fold,
"mean_outer_score": np.mean(outer_scores),
"std_outer_score": np.std(outer_scores),
}
# Set up nested CV
print("\nRunning nested time series CV...")
outer_cv = WalkForwardCV(
n_splits=3,
window_type="expanding",
test_size=100,
)
def inner_cv_factory(n_train: int) -> WalkForwardCV:
"""Create inner CV splitter based on training set size."""
return WalkForwardCV(
n_splits=3,
window_type="expanding",
test_size=max(20, n_train // 5),
)
nested_results = nested_time_series_cv(
X,
y,
model=GradientBoostingRegressor(random_state=42),
param_grid=param_grid,
outer_cv=outer_cv,
inner_cv_factory=inner_cv_factory,
)
# =============================================================================
# PART 4: Comparison - Nested vs Non-Nested
# =============================================================================
print("\n" + "=" * 70)
print("PART 4: Comparison - Nested vs Non-Nested")
print("=" * 70)
non_nested_score = np.sqrt(-grid_search.best_score_)
nested_score = nested_results["mean_outer_score"]
print(
f"""
Comparison of Approaches:
Non-Nested (GridSearchCV best_score_):
RMSE: {non_nested_score:.4f}
Issue: Uses same data for tuning and evaluation
Nested Time Series CV:
RMSE: {nested_score:.4f} +/- {nested_results['std_outer_score']:.4f}
Benefit: Outer test sets never see hyperparameter tuning
Difference: {nested_score - non_nested_score:.4f} RMSE
Relative optimism: {(nested_score - non_nested_score) / nested_score * 100:.1f}%
The nested score is typically HIGHER (worse) because it's an unbiased
estimate of future performance. The non-nested score is optimistically
biased by the hyperparameter selection process.
"""
)
# =============================================================================
# PART 5: Hyperparameter Stability Analysis
# =============================================================================
print("\n" + "=" * 70)
print("PART 5: Hyperparameter Stability Analysis")
print("=" * 70)
print("\nBest hyperparameters per outer fold:")
for i, params in enumerate(nested_results["best_params_per_fold"]):
print(f" Fold {i + 1}: {params}")
# Check stability
param_names = list(param_grid.keys())
print("\nParameter stability across folds:")
for param in param_names:
values = [p[param] for p in nested_results["best_params_per_fold"]]
unique_values = set(values)
if len(unique_values) == 1:
print(f" {param}: STABLE (always {values[0]})")
else:
print(f" {param}: VARIES ({unique_values})")
print(
"""
If hyperparameters vary significantly across outer folds, it suggests:
1. The optimal configuration depends on the time period
2. More data or simpler models might be needed
3. Consider using conservative (simpler) hyperparameters
"""
)
# =============================================================================
# PART 6: Practical Implementation Pattern
# =============================================================================
print("\n" + "=" * 70)
print("PART 6: Practical Implementation Pattern")
print("=" * 70)
print(
"""
Recommended workflow for hyperparameter tuning:
1. SPLIT DATA INTO THREE PARTS
- Training (for model fitting within inner CV)
- Validation (for hyperparameter selection)
- Test (for final evaluation, NEVER touched until the end)
2. USE TIME-AWARE CV IN BOTH LOOPS
- Outer: WalkForwardCV or SlidingWindowCV
- Inner: Same type, appropriate for training set size
3. REPORT THE OUTER SCORE
- This is your unbiased performance estimate
- The inner score (best_score_) is only for selecting hyperparameters
4. CHECK HYPERPARAMETER STABILITY
- If parameters vary wildly, consider simpler models
- Ensemble of fold-specific models is an option
5. FINAL MODEL
- Option A: Retrain on all data with consensus hyperparameters
- Option B: Use ensemble of per-fold models
"""
)
# Example: Final model with consensus hyperparameters
def get_consensus_params(params_list: list[dict]) -> dict:
"""Get most common value for each hyperparameter."""
from collections import Counter
consensus = {}
all_keys = params_list[0].keys()
for key in all_keys:
values = [p[key] for p in params_list]
most_common = Counter(values).most_common(1)[0][0]
consensus[key] = most_common
return consensus
consensus_params = get_consensus_params(nested_results["best_params_per_fold"])
print(f"\nConsensus hyperparameters: {consensus_params}")
# Train final model
final_model = GradientBoostingRegressor(**consensus_params, random_state=42)
final_model.fit(X, y)
print("\nFinal model trained on all data with consensus hyperparameters.")
# =============================================================================
# KEY TAKEAWAYS
# =============================================================================
print("\n" + "=" * 70)
print("KEY TAKEAWAYS")
print("=" * 70)
print(
"""
1. NEVER USE GridSearchCV.best_score_ AS YOUR PERFORMANCE ESTIMATE
- It's contaminated by the hyperparameter selection process
- Use nested CV for unbiased evaluation
2. BOTH LOOPS MUST RESPECT TEMPORAL ORDER
- Outer loop: WalkForwardCV for evaluation
- Inner loop: WalkForwardCV for tuning
3. EXPECT HIGHER (WORSE) SCORES WITH PROPER NESTED CV
- If your nested score ≈ non-nested score, you may have very stable data
- If nested >> non-nested, significant overfitting to validation period
4. CHECK HYPERPARAMETER STABILITY
- Varying params suggest regime changes or overfitting
- Stable params suggest robust model selection
5. FOR PRODUCTION
- Report nested CV score as expected performance
- Use consensus or median hyperparameters
- Retrain on all available data for deployment
"""
)
print("\n" + "=" * 70)
print("Example completed successfully!")
print("=" * 70)
======================================================================
PART 1: Data Generation
======================================================================
Generated AR(2) series with 495 observations
Features: 5 lagged values
Data shape: X=(495, 5), y=(495,)
======================================================================
PART 2: The Problem - Hyperparameter Leakage
======================================================================
Standard approach (WRONG for time series):
1. Run GridSearchCV with KFold to find best hyperparameters
2. Report CV score as expected performance
Problems:
- Future data influences hyperparameter selection
- CV score is optimistically biased
- Selected hyperparameters may not generalize
The score from GridSearchCV is NOT a valid estimate of future performance.
It's contaminated by the hyperparameter selection process.
WRONG: Standard GridSearchCV with time series data
Best params: {'learning_rate': 0.1, 'max_depth': 2, 'n_estimators': 50}
GridSearchCV score: 0.9917 RMSE
WARNING: This score is optimistically biased!
======================================================================
PART 3: Solution - Nested Cross-Validation
======================================================================
Nested CV structure:
OUTER LOOP (evaluation, never seen by inner loop):
Fold 1: Train [1-300] --> Test [301-400]
Fold 2: Train [1-400] --> Test [401-500]
INNER LOOP (hyperparameter tuning, within each outer train set):
Inner Fold 1: Train [1-150] --> Val [151-200]
Inner Fold 2: Train [1-200] --> Val [201-250]
Inner Fold 3: Train [1-250] --> Val [251-300]
The outer test sets are NEVER used for hyperparameter selection.
This gives an unbiased estimate of generalization performance.
Running nested time series CV...
Outer Fold 1:
Train size: 195, Test size: 100
Inner best params: {'learning_rate': 0.05, 'max_depth': 2, 'n_estimators': 50}
Inner best score: 1.0761 RMSE
Outer test score: 1.0541 RMSE
Outer Fold 2:
Train size: 295, Test size: 100
Inner best params: {'learning_rate': 0.05, 'max_depth': 2, 'n_estimators': 50}
Inner best score: 1.0562 RMSE
Outer test score: 1.1456 RMSE
Outer Fold 3:
Train size: 395, Test size: 100
Inner best params: {'learning_rate': 0.05, 'max_depth': 2, 'n_estimators': 50}
Inner best score: 1.0787 RMSE
Outer test score: 1.0474 RMSE
======================================================================
PART 4: Comparison - Nested vs Non-Nested
======================================================================
Comparison of Approaches:
Non-Nested (GridSearchCV best_score_):
RMSE: 0.9917
Issue: Uses same data for tuning and evaluation
Nested Time Series CV:
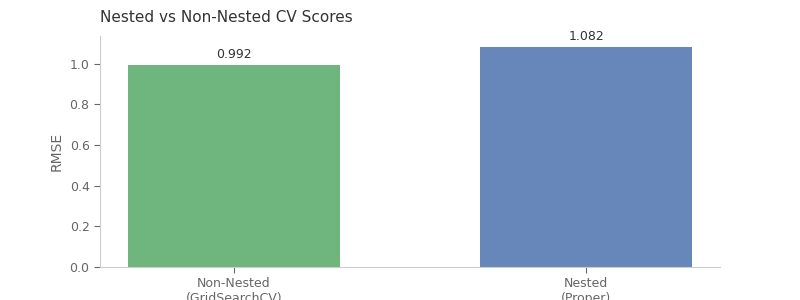
RMSE: 1.0824 +/- 0.0448
Benefit: Outer test sets never see hyperparameter tuning
Difference: 0.0907 RMSE
Relative optimism: 8.4%
The nested score is typically HIGHER (worse) because it's an unbiased
estimate of future performance. The non-nested score is optimistically
biased by the hyperparameter selection process.
======================================================================
PART 5: Hyperparameter Stability Analysis
======================================================================
Best hyperparameters per outer fold:
Fold 1: {'learning_rate': 0.05, 'max_depth': 2, 'n_estimators': 50}
Fold 2: {'learning_rate': 0.05, 'max_depth': 2, 'n_estimators': 50}
Fold 3: {'learning_rate': 0.05, 'max_depth': 2, 'n_estimators': 50}
Parameter stability across folds:
n_estimators: STABLE (always 50)
max_depth: STABLE (always 2)
learning_rate: STABLE (always 0.05)
If hyperparameters vary significantly across outer folds, it suggests:
1. The optimal configuration depends on the time period
2. More data or simpler models might be needed
3. Consider using conservative (simpler) hyperparameters
======================================================================
PART 6: Practical Implementation Pattern
======================================================================
Recommended workflow for hyperparameter tuning:
1. SPLIT DATA INTO THREE PARTS
- Training (for model fitting within inner CV)
- Validation (for hyperparameter selection)
- Test (for final evaluation, NEVER touched until the end)
2. USE TIME-AWARE CV IN BOTH LOOPS
- Outer: WalkForwardCV or SlidingWindowCV
- Inner: Same type, appropriate for training set size
3. REPORT THE OUTER SCORE
- This is your unbiased performance estimate
- The inner score (best_score_) is only for selecting hyperparameters
4. CHECK HYPERPARAMETER STABILITY
- If parameters vary wildly, consider simpler models
- Ensemble of fold-specific models is an option
5. FINAL MODEL
- Option A: Retrain on all data with consensus hyperparameters
- Option B: Use ensemble of per-fold models
Consensus hyperparameters: {'learning_rate': 0.05, 'max_depth': 2, 'n_estimators': 50}
Final model trained on all data with consensus hyperparameters.
======================================================================
KEY TAKEAWAYS
======================================================================
1. NEVER USE GridSearchCV.best_score_ AS YOUR PERFORMANCE ESTIMATE
- It's contaminated by the hyperparameter selection process
- Use nested CV for unbiased evaluation
2. BOTH LOOPS MUST RESPECT TEMPORAL ORDER
- Outer loop: WalkForwardCV for evaluation
- Inner loop: WalkForwardCV for tuning
3. EXPECT HIGHER (WORSE) SCORES WITH PROPER NESTED CV
- If your nested score ≈ non-nested score, you may have very stable data
- If nested >> non-nested, significant overfitting to validation period
4. CHECK HYPERPARAMETER STABILITY
- Varying params suggest regime changes or overfitting
- Stable params suggest robust model selection
5. FOR PRODUCTION
- Report nested CV score as expected performance
- Use consensus or median hyperparameters
- Retrain on all available data for deployment
======================================================================
Example completed successfully!
======================================================================
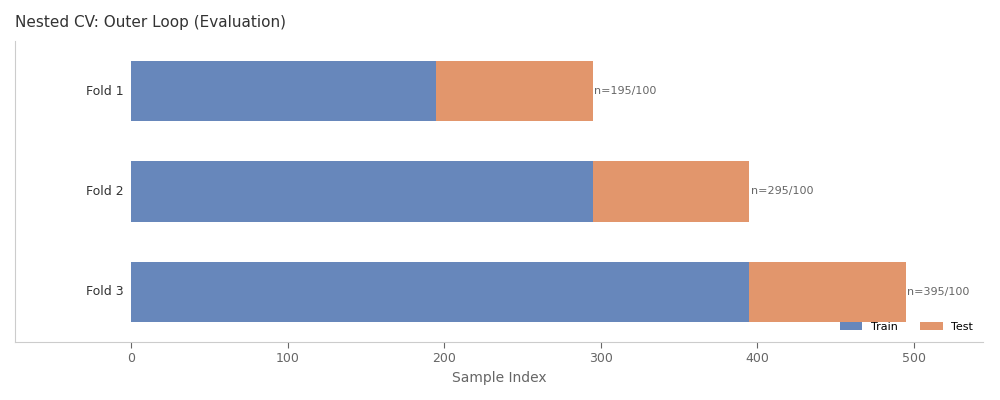
Nested CV Structure Visualization¶
This shows the nested cross-validation structure: - Outer loop: evaluation (5 folds) - Inner loop (not shown): hyperparameter tuning within each outer train set
import matplotlib.pyplot as plt
fig, ax = plt.subplots(figsize=(10, 4))
# Show outer CV structure
cv = WalkForwardCV(n_splits=3, window_type="expanding", test_size=100)
CVFoldsDisplay.from_cv(cv, X, y).plot(ax=ax, title="Nested CV: Outer Loop (Evaluation)")
plt.tight_layout()
plt.show()
Score Comparison: Nested vs Non-Nested¶
Non-nested CV gives optimistically biased scores because hyperparameter selection uses the same data as evaluation.
results = {
"Non-Nested\n(GridSearchCV)": {"RMSE": non_nested_score},
"Nested\n(Proper)": {"RMSE": nested_score},
}
display = MetricComparisonDisplay.from_dict(results, lower_is_better={"RMSE": True})
display.plot(title="Nested vs Non-Nested CV Scores", show_values=True)
plt.show()
Total running time of the script: (0 minutes 13.351 seconds)