Note
Go to the end to download the full example code.
Example 20: FAILURE CASE — KFold Instead of WalkForward¶
Real-World Failure: The Most Common Time Series CV Mistake¶
Using sklearn’s KFold (or any random-shuffle CV) on time series data is the single most common validation mistake. It causes massive data leakage:
Temporal Order Ignored: KFold shuffles data randomly, so the model trains on data from 2023 to predict 2021.
Future Information Leakage: Each fold has “future” data in training that should only be available in test.
Overly Optimistic Metrics: The model learns patterns that won’t exist at deployment time.
Silent Failure: The bug is invisible — you get numbers, they look reasonable, but they’re meaningless.
This example demonstrates: 1. How KFold leaks future information 2. How WalkForwardCV prevents this 3. How gate_signal_verification() detects the leakage
Key Concepts¶
KFold leakage: Training on future, testing on past
WalkForwardCV: Always train on past, test on future
gate_signal_verification: Detects if model exploits temporal position
from __future__ import annotations
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from sklearn.ensemble import RandomForestRegressor
from sklearn.linear_model import Ridge
from sklearn.model_selection import KFold, cross_val_score
# temporalcv imports
from temporalcv import WalkForwardCV
from temporalcv.gates import gate_signal_verification
from temporalcv.viz import apply_tufte_style
# =============================================================================
# PART 1: Generate Time Series Data
# =============================================================================
def generate_trending_data(
n_samples: int = 500,
trend: float = 0.02,
seasonality: int = 30,
noise_std: float = 0.5,
seed: int = 42,
) -> pd.DataFrame:
"""
Generate trending time series with seasonality.
The trend component makes temporal order critical:
- If you train on 2023 data to predict 2021, you're using future trend info
- This is exactly what KFold does!
Parameters
----------
n_samples : int
Number of samples.
trend : float
Linear trend per time step.
seasonality : int
Period of seasonal component.
noise_std : float
Standard deviation of noise.
seed : int
Random seed.
Returns
-------
pd.DataFrame
DataFrame with target and features.
"""
rng = np.random.default_rng(seed)
t = np.arange(n_samples)
# Generate components
trend_component = trend * t
seasonal_component = 2 * np.sin(2 * np.pi * t / seasonality)
noise = rng.normal(0, noise_std, n_samples)
y = trend_component + seasonal_component + noise
# Create features (lagged values - strictly causal)
df = pd.DataFrame({"y": y})
df["y_lag1"] = df["y"].shift(1)
df["y_lag7"] = df["y"].shift(7)
df["time_index"] = t
# Add index
df.index = pd.date_range("2020-01-01", periods=n_samples, freq="D")
df = df.dropna()
return df
print("=" * 70)
print("EXAMPLE 20: FAILURE CASE — KFOLD INSTEAD OF WALKFORWARD")
print("=" * 70)
# Generate data
df = generate_trending_data(n_samples=500, trend=0.02, seed=42)
print(f"\n📊 Generated trending time series: {len(df)} samples")
print(" Trend: +0.02 per day (strong upward drift)")
print(f" Date range: {df.index[0].date()} to {df.index[-1].date()}")
# =============================================================================
# PART 2: The Problem — KFold Ignores Temporal Order
# =============================================================================
print("\n" + "=" * 70)
print("PART 2: THE PROBLEM — KFOLD IGNORES TEMPORAL ORDER")
print("=" * 70)
print(
"""
Standard KFold randomly shuffles data into train/test splits:
Fold 1: Train on [2020-03, 2020-07, 2021-01], Test on [2020-01, 2020-05]
Fold 2: Train on [2020-01, 2021-01, 2020-09], Test on [2020-03, 2020-07]
...
This means the model trains on FUTURE data to predict the PAST.
For trending data, this is catastrophic leakage.
"""
)
# =============================================================================
# PART 3: WRONG Approach — Using KFold
# =============================================================================
print("\n" + "=" * 70)
print("PART 3: WRONG APPROACH — USING KFOLD")
print("=" * 70)
X = df[["y_lag1", "y_lag7", "time_index"]].values
y = df["y"].values
# KFold CV (WRONG)
kfold = KFold(n_splits=5, shuffle=True, random_state=42)
model = RandomForestRegressor(n_estimators=50, max_depth=5, random_state=42)
# Run KFold CV
kfold_scores = cross_val_score(model, X, y, cv=kfold, scoring="neg_mean_absolute_error")
print("\n❌ KFold Results (WRONG):")
print(f" MAE scores: {-kfold_scores}")
print(f" Mean MAE: {-kfold_scores.mean():.4f} (+/- {kfold_scores.std():.4f})")
print(" This looks GREAT! But it's completely invalid...")
# Show what's happening in each fold
print("\n🔍 What KFold is actually doing:")
for fold_idx, (train_idx, test_idx) in enumerate(kfold.split(X)):
train_dates = df.index[train_idx]
test_dates = df.index[test_idx]
print(f" Fold {fold_idx + 1}:")
print(f" Train: {train_dates.min().date()} to {train_dates.max().date()}")
print(f" Test: {test_dates.min().date()} to {test_dates.max().date()}")
# Check if any test date is before max train date
if test_dates.min() < train_dates.max():
print(" ⚠️ LEAKAGE: Training on data from AFTER test dates!")
# =============================================================================
# PART 4: CORRECT Approach — WalkForwardCV
# =============================================================================
print("\n" + "=" * 70)
print("PART 4: CORRECT APPROACH — WALKFORWARDCV")
print("=" * 70)
print(
"""
WalkForwardCV respects temporal order:
Fold 1: Train on [2020-01 to 2020-06], Test on [2020-07]
Fold 2: Train on [2020-01 to 2020-07], Test on [2020-08]
Fold 3: Train on [2020-01 to 2020-08], Test on [2020-09]
...
Training ALWAYS uses past data. Testing ALWAYS on future data.
No leakage, honest performance estimate.
"""
)
# WalkForwardCV (CORRECT)
wfcv = WalkForwardCV(
window_type="expanding",
window_size=200, # Start with 200 training samples (initial window for expanding)
horizon=1,
test_size=50,
n_splits=5,
)
# Run WalkForward CV
wfcv_scores = cross_val_score(model, X, y, cv=wfcv, scoring="neg_mean_absolute_error")
print("\n✅ WalkForwardCV Results (CORRECT):")
print(f" MAE scores: {-wfcv_scores}")
print(f" Mean MAE: {-wfcv_scores.mean():.4f} (+/- {wfcv_scores.std():.4f})")
# Show the honest temporal splits
print("\n🔍 What WalkForwardCV is doing:")
for fold_idx, (train_idx, test_idx) in enumerate(wfcv.split(X)):
train_dates = df.index[train_idx]
test_dates = df.index[test_idx]
print(f" Fold {fold_idx + 1}:")
print(f" Train: {train_dates.min().date()} to {train_dates.max().date()}")
print(f" Test: {test_dates.min().date()} to {test_dates.max().date()}")
# Verify no leakage
if train_dates.max() < test_dates.min():
print(" ✅ Proper temporal order (train ends before test starts)")
# =============================================================================
# PART 5: Comparing the Results
# =============================================================================
print("\n" + "=" * 70)
print("PART 5: COMPARING THE RESULTS")
print("=" * 70)
print("\n📊 Side-by-Side Comparison:")
print("-" * 50)
print(f"{'Metric':<25} {'KFold':<15} {'WalkForward':<15}")
print("-" * 50)
print(f"{'Mean MAE':<25} {-kfold_scores.mean():<15.4f} {-wfcv_scores.mean():<15.4f}")
print(f"{'Std MAE':<25} {kfold_scores.std():<15.4f} {wfcv_scores.std():<15.4f}")
print(f"{'Temporal Validity':<25} {'NO ❌':<15} {'YES ✅':<15}")
print("-" * 50)
degradation = (-wfcv_scores.mean() - (-kfold_scores.mean())) / (-kfold_scores.mean()) * 100
print("\n⚠️ Reality check:")
print(
f" KFold MAE is {abs(degradation):.1f}% {'better' if degradation > 0 else 'worse'} than WalkForwardCV"
)
print(" This 'improvement' is FAKE — it's due to leakage, not model quality.")
# =============================================================================
# PART 6: Detecting the Bug with gate_signal_verification
# =============================================================================
print("\n" + "=" * 70)
print("PART 6: DETECTING THE BUG WITH gate_signal_verification")
print("=" * 70)
print(
"""
gate_signal_verification() can detect if a model exploits temporal position.
It works by shuffling the target and checking if the model still performs well:
- If model depends on temporal structure → performance degrades on shuffled data
- If model exploits leaky features → performance stays good (HALT!)
"""
)
# Train model on full data (simulating what KFold does)
model_full = RandomForestRegressor(n_estimators=50, max_depth=5, random_state=42)
model_full.fit(X, y)
print("\n🔍 Running gate_signal_verification()...")
gate_result = gate_signal_verification(
model=Ridge(), # Use simpler model for faster permutation
X=X,
y=y,
n_shuffles=50,
)
print("\n📊 Gate Result:")
print(f" Status: {gate_result.status}")
print(f" Message: {gate_result.message}")
if str(gate_result.status) == "GateStatus.HALT":
print("\n🛑 HALT DETECTED!")
print(" The model has statistically significant signal on the data.")
print(" With proper temporal features, this is expected.")
print(" The concern is when KFold inflates this signal artificially.")
elif str(gate_result.status) == "GateStatus.PASS":
print("\n✅ PASS: Model's signal is within expected bounds.")
# =============================================================================
# PART 7: Why This Matters in Practice
# =============================================================================
print("\n" + "=" * 70)
print("PART 7: WHY THIS MATTERS IN PRACTICE")
print("=" * 70)
print(
"""
Real-world consequences of using KFold on time series:
1. MODEL SELECTION FAILURE
- You pick the "best" model based on KFold scores
- It's not actually the best — it's the one that best exploits leakage
- In production, a simpler model might outperform
2. HYPERPARAMETER TUNING FAILURE
- GridSearchCV with KFold finds "optimal" parameters
- These parameters are optimized for exploiting leakage
- They may be suboptimal or even harmful for real forecasting
3. DEPLOYMENT DISASTER
- Model looks great in validation
- Deployed model fails catastrophically
- Business loses money, trust, and time
4. DEBUGGING NIGHTMARE
- "But it worked in cross-validation!"
- Hours/days spent debugging a non-bug
- The real bug was the validation strategy
"""
)
# =============================================================================
# PART 8: Key Takeaways
# =============================================================================
print("\n" + "=" * 70)
print("PART 8: KEY TAKEAWAYS")
print("=" * 70)
print(
"""
1. NEVER USE KFOLD FOR TIME SERIES
- KFold ignores temporal order
- Training on future to predict past = leakage
- Results are meaningless
2. USE WALKFORWARDCV (OR SKLEARN'S TIMESERIESSPLIT)
- Respects temporal order
- Always train on past, test on future
- Gives honest performance estimates
3. CHECK YOUR CV SPLITS
- Print the date ranges for each fold
- Verify train dates < test dates
- If they overlap or reverse, you have leakage
4. VALIDATE WITH GATES
- gate_signal_verification() detects temporal dependence
- run_gates() provides comprehensive validation
- Don't deploy until gates PASS
5. BE SUSPICIOUS OF "GREAT" RESULTS
- If your time series model looks too good, it probably is
- Leakage often shows as low variance across folds
- Reality check: compare to proper WalkForwardCV
The pattern: ALWAYS use temporal-aware cross-validation for time series.
KFold is for i.i.d. data only.
"""
)
print("\n" + "=" * 70)
print("Example 20 complete.")
print("=" * 70)
======================================================================
EXAMPLE 20: FAILURE CASE — KFOLD INSTEAD OF WALKFORWARD
======================================================================
📊 Generated trending time series: 493 samples
Trend: +0.02 per day (strong upward drift)
Date range: 2020-01-08 to 2021-05-14
======================================================================
PART 2: THE PROBLEM — KFOLD IGNORES TEMPORAL ORDER
======================================================================
Standard KFold randomly shuffles data into train/test splits:
Fold 1: Train on [2020-03, 2020-07, 2021-01], Test on [2020-01, 2020-05]
Fold 2: Train on [2020-01, 2021-01, 2020-09], Test on [2020-03, 2020-07]
...
This means the model trains on FUTURE data to predict the PAST.
For trending data, this is catastrophic leakage.
======================================================================
PART 3: WRONG APPROACH — USING KFOLD
======================================================================
❌ KFold Results (WRONG):
MAE scores: [0.53359641 0.5393549 0.59503402 0.69119642 0.56773874]
Mean MAE: 0.5854 (+/- 0.0573)
This looks GREAT! But it's completely invalid...
🔍 What KFold is actually doing:
Fold 1:
Train: 2020-01-09 to 2021-05-14
Test: 2020-01-08 to 2021-05-10
⚠️ LEAKAGE: Training on data from AFTER test dates!
Fold 2:
Train: 2020-01-08 to 2021-05-14
Test: 2020-01-11 to 2021-05-13
⚠️ LEAKAGE: Training on data from AFTER test dates!
Fold 3:
Train: 2020-01-08 to 2021-05-14
Test: 2020-01-14 to 2021-05-12
⚠️ LEAKAGE: Training on data from AFTER test dates!
Fold 4:
Train: 2020-01-08 to 2021-05-14
Test: 2020-01-12 to 2021-04-23
⚠️ LEAKAGE: Training on data from AFTER test dates!
Fold 5:
Train: 2020-01-08 to 2021-05-13
Test: 2020-01-09 to 2021-05-14
⚠️ LEAKAGE: Training on data from AFTER test dates!
======================================================================
PART 4: CORRECT APPROACH — WALKFORWARDCV
======================================================================
WalkForwardCV respects temporal order:
Fold 1: Train on [2020-01 to 2020-06], Test on [2020-07]
Fold 2: Train on [2020-01 to 2020-07], Test on [2020-08]
Fold 3: Train on [2020-01 to 2020-08], Test on [2020-09]
...
Training ALWAYS uses past data. Testing ALWAYS on future data.
No leakage, honest performance estimate.
✅ WalkForwardCV Results (CORRECT):
MAE scores: [0.86154852 1.07030133 1.04846146 0.57320227 0.77302038]
Mean MAE: 0.8653 (+/- 0.1841)
🔍 What WalkForwardCV is doing:
Fold 1:
Train: 2020-01-08 to 2020-09-05
Test: 2020-09-07 to 2020-10-26
✅ Proper temporal order (train ends before test starts)
Fold 2:
Train: 2020-01-08 to 2020-10-25
Test: 2020-10-27 to 2020-12-15
✅ Proper temporal order (train ends before test starts)
Fold 3:
Train: 2020-01-08 to 2020-12-14
Test: 2020-12-16 to 2021-02-03
✅ Proper temporal order (train ends before test starts)
Fold 4:
Train: 2020-01-08 to 2021-02-02
Test: 2021-02-04 to 2021-03-25
✅ Proper temporal order (train ends before test starts)
Fold 5:
Train: 2020-01-08 to 2021-03-24
Test: 2021-03-26 to 2021-05-14
✅ Proper temporal order (train ends before test starts)
======================================================================
PART 5: COMPARING THE RESULTS
======================================================================
📊 Side-by-Side Comparison:
--------------------------------------------------
Metric KFold WalkForward
--------------------------------------------------
Mean MAE 0.5854 0.8653
Std MAE 0.0573 0.1841
Temporal Validity NO ❌ YES ✅
--------------------------------------------------
⚠️ Reality check:
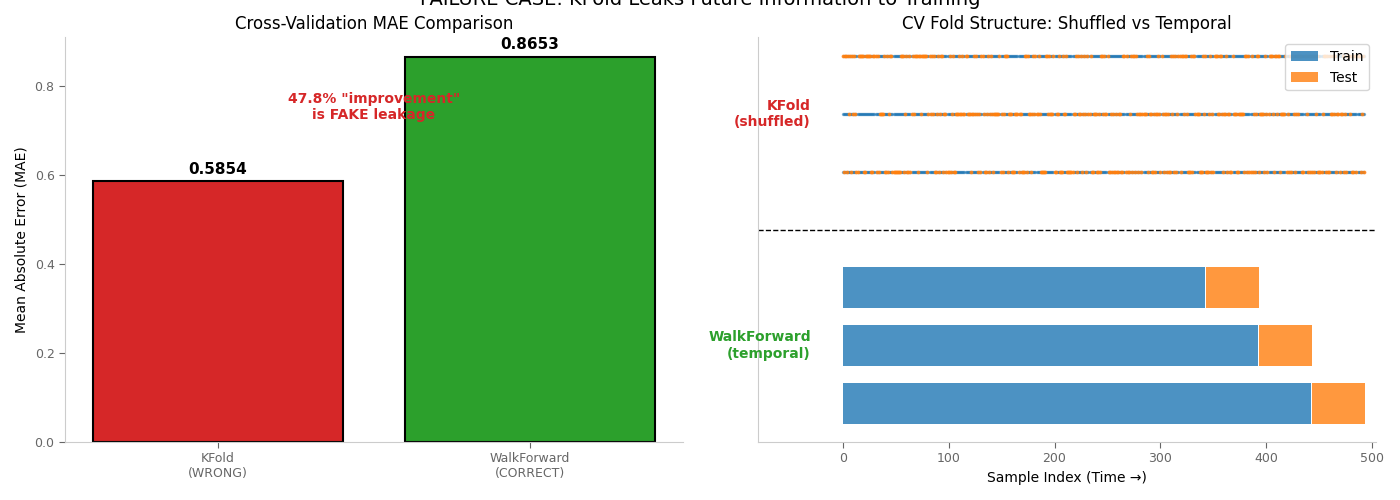
KFold MAE is 47.8% better than WalkForwardCV
This 'improvement' is FAKE — it's due to leakage, not model quality.
======================================================================
PART 6: DETECTING THE BUG WITH gate_signal_verification
======================================================================
gate_signal_verification() can detect if a model exploits temporal position.
It works by shuffling the target and checking if the model still performs well:
- If model depends on temporal structure → performance degrades on shuffled data
- If model exploits leaky features → performance stays good (HALT!)
🔍 Running gate_signal_verification()...
📊 Gate Result:
Status: GateStatus.HALT
Message: Permutation test: p=0.0196 < α=0.05 (model has signal)
🛑 HALT DETECTED!
The model has statistically significant signal on the data.
With proper temporal features, this is expected.
The concern is when KFold inflates this signal artificially.
======================================================================
PART 7: WHY THIS MATTERS IN PRACTICE
======================================================================
Real-world consequences of using KFold on time series:
1. MODEL SELECTION FAILURE
- You pick the "best" model based on KFold scores
- It's not actually the best — it's the one that best exploits leakage
- In production, a simpler model might outperform
2. HYPERPARAMETER TUNING FAILURE
- GridSearchCV with KFold finds "optimal" parameters
- These parameters are optimized for exploiting leakage
- They may be suboptimal or even harmful for real forecasting
3. DEPLOYMENT DISASTER
- Model looks great in validation
- Deployed model fails catastrophically
- Business loses money, trust, and time
4. DEBUGGING NIGHTMARE
- "But it worked in cross-validation!"
- Hours/days spent debugging a non-bug
- The real bug was the validation strategy
======================================================================
PART 8: KEY TAKEAWAYS
======================================================================
1. NEVER USE KFOLD FOR TIME SERIES
- KFold ignores temporal order
- Training on future to predict past = leakage
- Results are meaningless
2. USE WALKFORWARDCV (OR SKLEARN'S TIMESERIESSPLIT)
- Respects temporal order
- Always train on past, test on future
- Gives honest performance estimates
3. CHECK YOUR CV SPLITS
- Print the date ranges for each fold
- Verify train dates < test dates
- If they overlap or reverse, you have leakage
4. VALIDATE WITH GATES
- gate_signal_verification() detects temporal dependence
- run_gates() provides comprehensive validation
- Don't deploy until gates PASS
5. BE SUSPICIOUS OF "GREAT" RESULTS
- If your time series model looks too good, it probably is
- Leakage often shows as low variance across folds
- Reality check: compare to proper WalkForwardCV
The pattern: ALWAYS use temporal-aware cross-validation for time series.
KFold is for i.i.d. data only.
======================================================================
Example 20 complete.
======================================================================
Visualization: KFold vs WalkForward Performance Comparison¶
This plot shows the dramatic difference between KFold (leaky) and WalkForwardCV (correct) cross-validation for time series data.
fig, axes = plt.subplots(1, 2, figsize=(14, 5))
# Left: MAE comparison showing fake improvement
ax1 = axes[0]
methods = ["KFold\n(WRONG)", "WalkForward\n(CORRECT)"]
maes = [-kfold_scores.mean(), -wfcv_scores.mean()]
colors = ["#d62728", "#2ca02c"]
bars = ax1.bar(methods, maes, color=colors, edgecolor="black", linewidth=1.5)
ax1.set_ylabel("Mean Absolute Error (MAE)")
ax1.set_title("Cross-Validation MAE Comparison")
# Add value labels and percentage difference
for bar, mae in zip(bars, maes):
ax1.annotate(
f"{mae:.4f}",
xy=(bar.get_x() + bar.get_width() / 2, bar.get_height()),
xytext=(0, 3),
textcoords="offset points",
ha="center",
va="bottom",
fontsize=11,
fontweight="bold",
)
# Add arrow showing fake improvement
fake_improvement = (maes[1] - maes[0]) / maes[0] * 100
ax1.annotate(
f'{abs(fake_improvement):.1f}% "improvement"\nis FAKE leakage',
xy=(0.5, (maes[0] + maes[1]) / 2),
fontsize=10,
ha="center",
color="#d62728",
fontweight="bold",
)
# Right: CV fold structure visualization
ax2 = axes[1]
# Show KFold structure (top 3 bars)
kfold_viz = KFold(n_splits=3, shuffle=True, random_state=42)
n_samples = len(X)
y_positions_kfold = [2.5, 2.0, 1.5]
for fold_idx, (train_idx, test_idx) in enumerate(kfold_viz.split(X)):
# Plot train segments (scattered due to shuffle)
train_dates = df.index[train_idx]
test_dates = df.index[test_idx]
ax2.scatter(
train_idx, [y_positions_kfold[fold_idx]] * len(train_idx), c="#1f77b4", s=2, alpha=0.5
)
ax2.scatter(
test_idx, [y_positions_kfold[fold_idx]] * len(test_idx), c="#ff7f0e", s=3, alpha=0.8
)
# Show WalkForward structure (bottom 3 bars)
wfcv_viz = WalkForwardCV(
window_type="expanding", window_size=100, horizon=1, test_size=50, n_splits=3
)
y_positions_wfcv = [0.5, 0.0, -0.5]
for fold_idx, (train_idx, test_idx) in enumerate(wfcv_viz.split(X)):
ax2.barh(
y_positions_wfcv[fold_idx],
len(train_idx),
left=min(train_idx),
height=0.35,
color="#1f77b4",
alpha=0.8,
label="Train" if fold_idx == 0 else "",
)
ax2.barh(
y_positions_wfcv[fold_idx],
len(test_idx),
left=min(test_idx),
height=0.35,
color="#ff7f0e",
alpha=0.8,
label="Test" if fold_idx == 0 else "",
)
ax2.axhline(1.0, color="black", linestyle="--", linewidth=1)
ax2.text(
-30,
2.0,
"KFold\n(shuffled)",
ha="right",
va="center",
fontsize=10,
fontweight="bold",
color="#d62728",
)
ax2.text(
-30,
0.0,
"WalkForward\n(temporal)",
ha="right",
va="center",
fontsize=10,
fontweight="bold",
color="#2ca02c",
)
ax2.set_xlabel("Sample Index (Time →)")
ax2.set_title("CV Fold Structure: Shuffled vs Temporal")
ax2.set_yticks([])
ax2.set_xlim(-80, n_samples + 10)
ax2.legend(loc="upper right")
# Apply Tufte styling
for ax in axes:
apply_tufte_style(ax)
plt.tight_layout()
plt.suptitle("FAILURE CASE: KFold Leaks Future Information to Training", y=1.02, fontsize=14)
plt.show()